What is an Agent
With the continuous development of artificial intelligence technology, agents, which are systems capable of autonomous decision-making and task execution, are becoming a hot research direction in the AI field. This article will explore the differences between agents and large models, analyze the working principles of agents and their evaluation standards, and conduct in-depth evaluations of three representative agent products: Zhipu Thinking Auto GLM, Coze, and Nano AI.
Differences Between Agents and Large Models
Many may wonder:
“Why do we need agents when we already have large models? Can’t large models achieve the same results as agents?”
Let’s first look at the definitions to understand the differences:
Large models are AI models based on deep learning, possessing billions to trillions of parameters. They can learn complex patterns from massive amounts of data and have capabilities for text generation, logical reasoning, and multi-task processing, representing a core breakthrough direction in the current AI field.
AI agents, on the other hand, have a large language model (LLM) as their brain and possess autonomous decision-making and action capabilities. They can independently use tools, call APIs, plan steps, and execute tasks based on goals. Agents enable AI to autonomously complete tasks, acting on behalf of humans to achieve specific objectives.
Thus, large models provide task methods, but execution still requires human involvement; agents can make independent decisions and proactively execute tasks, directly yielding the desired results. Lilian Weng also mentioned that “agents are autonomous agents driven by large language models” with three core capabilities: planning, action, and memory.
Working Principles and Evaluation of Agents
1. Internal Working Principles of Agents
Agents, supported by LLMs, complete specific tasks by invoking external tools. This is one of the foundational mechanisms for building intelligent agents.
In the LangChain official documentation section “How to migrate from legacy LangChain agents to LangGraph,” an example using magic_function(3) demonstrates the complete process of how language models (LLMs) call external tools, including tool definition, binding with the model, generating and executing tool calls, and returning the final results.
In the LangChain framework, external functions are integrated into the LLM’s reasoning process in a structured manner, enhancing the model’s functionality and flexibility. This is a key illustration for understanding the interaction mechanism between LangChain agents and tools.
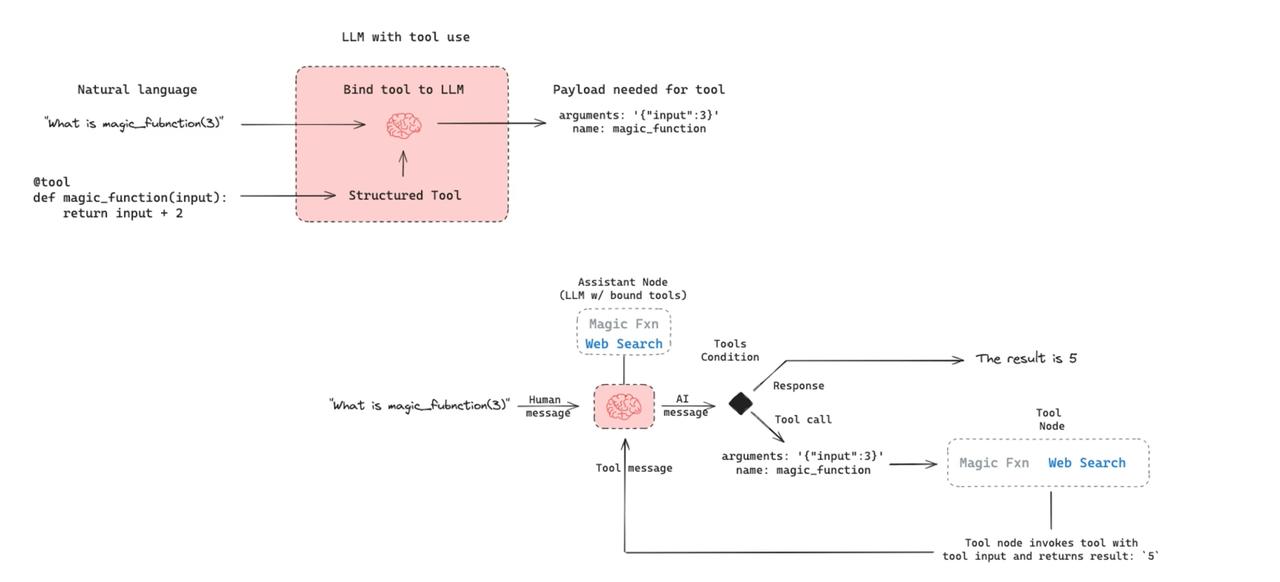
This diagram illustrates the calling mechanism of AI agents and their principles, showing how language models (LLMs) understand and execute user commands through bound external tools. When users pose questions in natural language, the LLM parses them into structured tool call requests, initiates calls based on tool definitions, retrieves results, and generates final answers. This process reflects the agent’s capability of “understanding → decision-making → action → answering,” which is the foundational mechanism for completing complex tasks.
2. Evaluation Principles of Agents
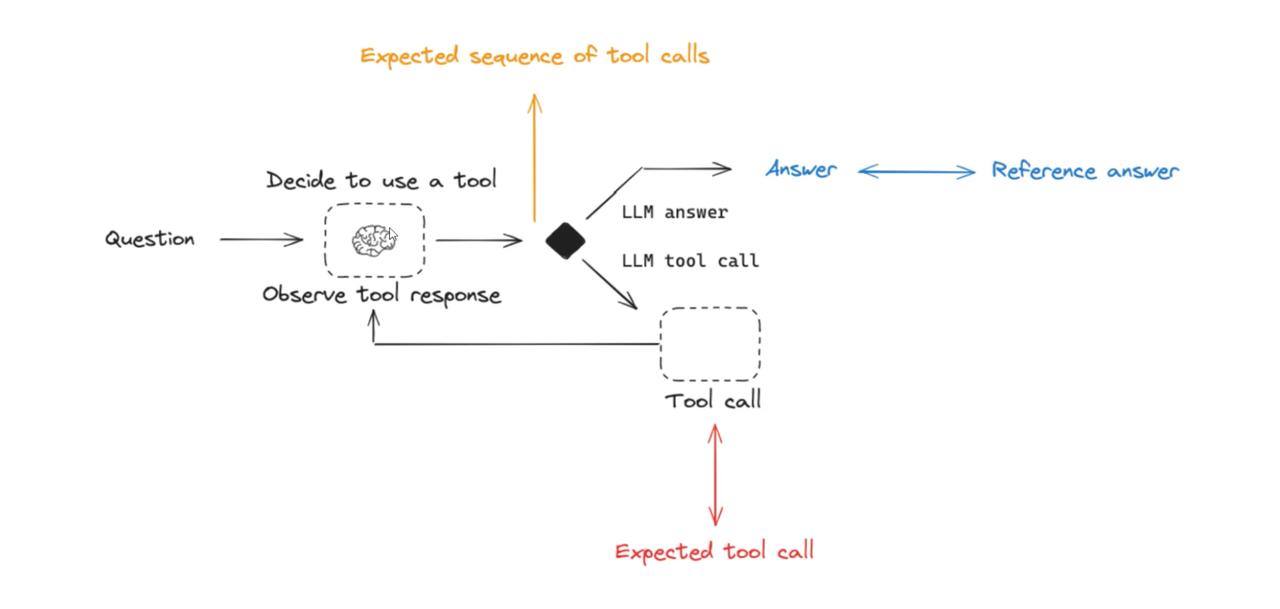
When evaluating agents, the evaluation logic for tool calling decisions and actions is as follows: when an agent receives a user question, the language model needs to determine whether to use a tool and make the corresponding call. If a tool is called, it enters the tool execution phase and continues reasoning based on the results; otherwise, it answers directly. The evaluation process focuses not only on whether the final answer is close to the reference answer (blue arrow) but also on whether the model correctly called the tool as expected (red arrow) and whether the calling sequence is reasonable (orange arrow). This reflects a dual evaluation standard for the agent’s behavior path and final output.
The diagram provides an example of a tool-calling agent, demonstrating how the language model (LLM) determines whether to call a tool, executes the tool call, and returns the final result.
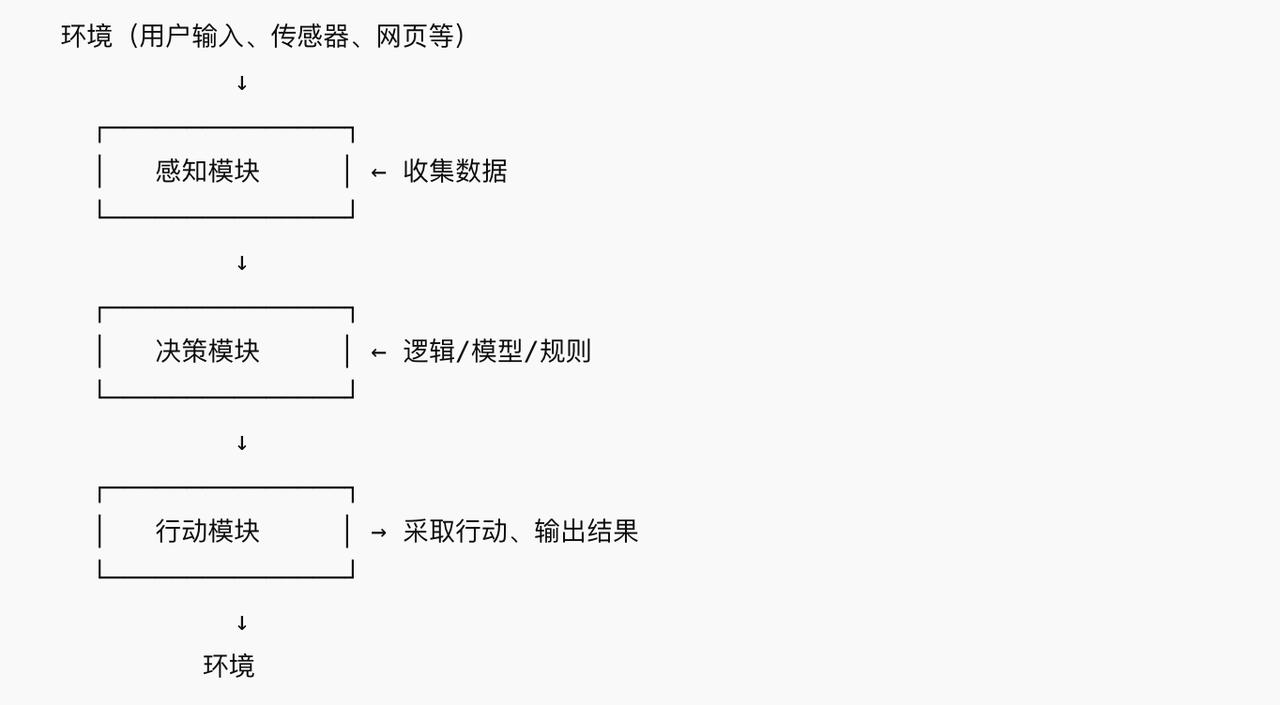
3. Core Components of an Agent
Typically, an agent consists of the following parts:
- Perception: Acquiring information from the environment, such as reading sensors, receiving user input, and obtaining API data. Example: A customer service agent extracts the user’s intent from input.
- Decision-making (Reasoning / Planning): Judging the current situation based on perceived information and deciding what to do next. Techniques may include rule systems, machine learning, reinforcement learning, and logical reasoning.
- Execution (Action): Performing actions based on decisions, such as calling APIs, sending messages, or controlling robot movements.
- Goal or Task System: Agents typically have a clear goal, such as completing orders, answering questions, or planning routes.
Feedback and Learning (optional): Some advanced agents have self-feedback mechanisms, continuously optimizing behavior strategies through reinforcement learning.
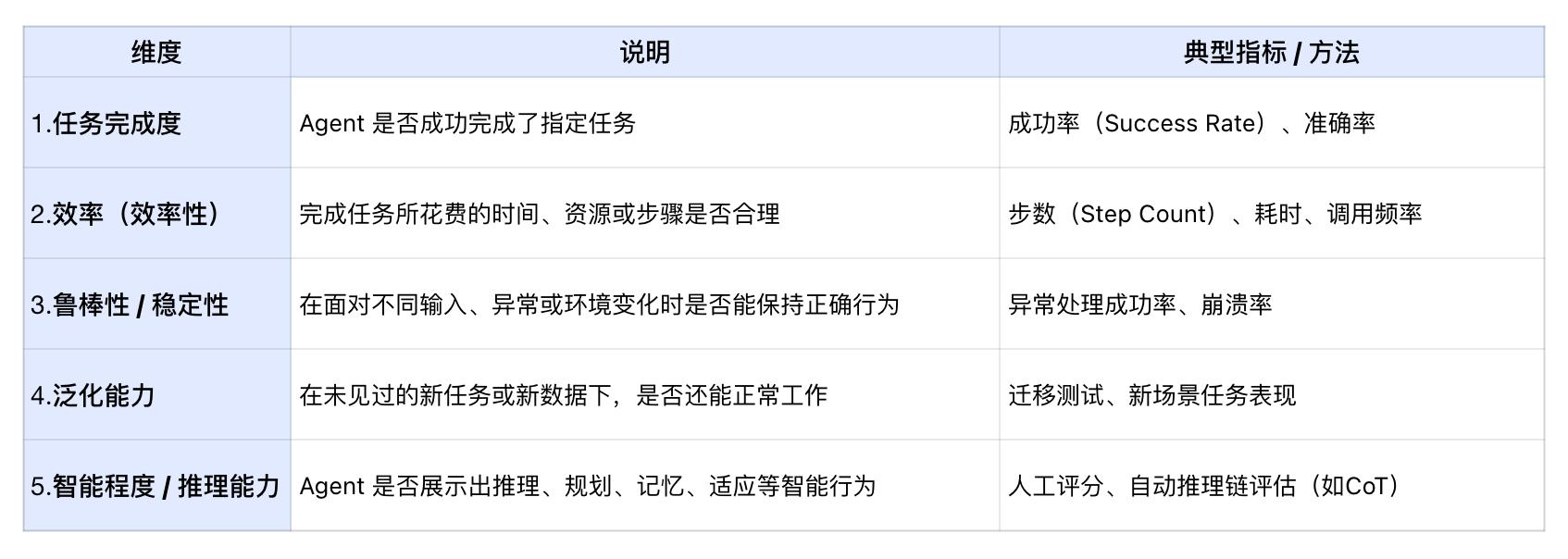
Evaluation Dimensions
The process of evaluating agents essentially assesses whether they can efficiently, accurately, and stably achieve task objectives, typically including the following dimensions:
Key Evaluation Points:
✅ Did it complete the task according to the predetermined process?
✅ Could it handle abnormal inputs?
✅ Did it successfully call the corresponding API?
For example, if you trained an agent to help users “check the weather and write a daily report,” you could evaluate it as follows:
Input Task: “What is the weather like in Beijing today? Please write a daily report summary.”
Evaluation Points:
- Did it correctly use the weather API tool?
- Did it produce a structurally complete and reasonable daily report?
- Could it gracefully degrade when encountering API failures?
- How many steps were called in total? Were there redundancies?
You can also design a set of standard tasks + a set of boundary/interference tasks for automatic scoring of output results or manual review.
Evaluation of Final Results, Individual Steps, and Trajectories
- Evaluate the agent’s overall performance on tasks, treating it as a black box and simply assessing whether it completed the work.
- Evaluate individual steps of the agent—whether the LLM correctly called a specific tool and passed the correct parameters.
- Evaluate individual steps of the agent—whether the LLM correctly called a specific tool and passed the correct parameters.
Three Domestic Agent Products
1. ByteDance Coze
Link: Coze
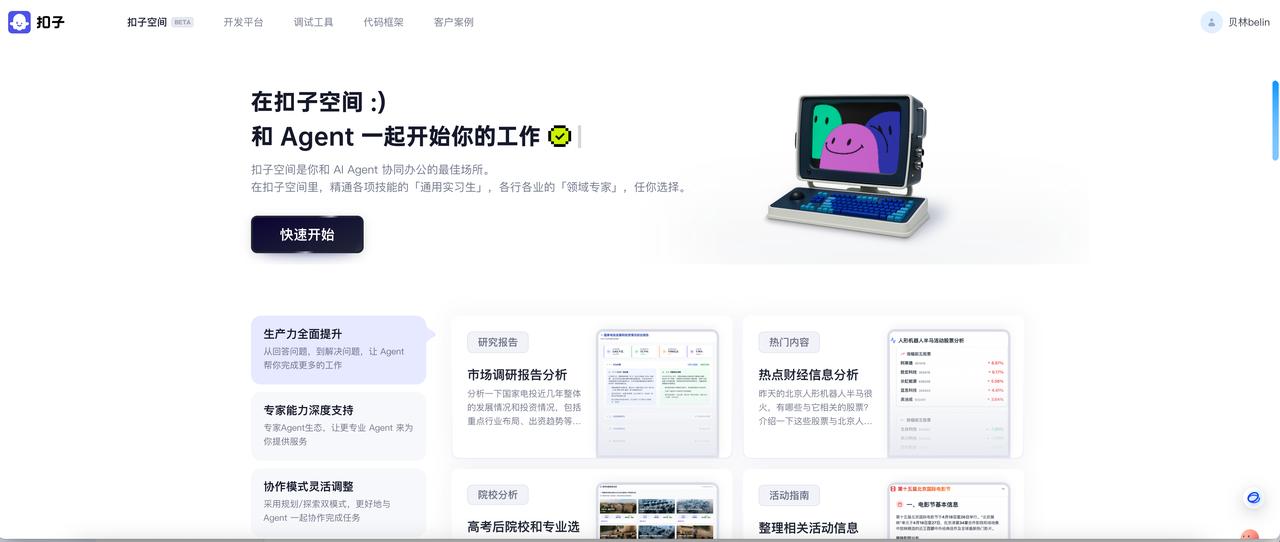
Positioning: An AI collaborative office platform launched by ByteDance in April 2025, focusing on low-code development and enterprise-level scenarios.
Core Capabilities:
- Three modes for task execution: Exploration mode (quick tasks), Planning mode (complex tasks), and Free mode, supporting dynamic sub-task decomposition and tool invocation (e.g., browser, code editor).
- Expert agent ecosystem: Introduces experts from various fields, such as Huatai A-share observation assistants and user research experts, providing in-depth industry services.
- Multimodal integration: Supports Feishu multi-dimensional tables, Gaode Maps, and other MCP extensions, outputting structured reports like PPT and Feishu documents. Advantages: User-friendly interface, complete plugin store, and workflow store ecosystem, suitable for non-technical personnel to quickly get started.
2. Zhipu Thinking Auto GLM
Link: Auto GLM
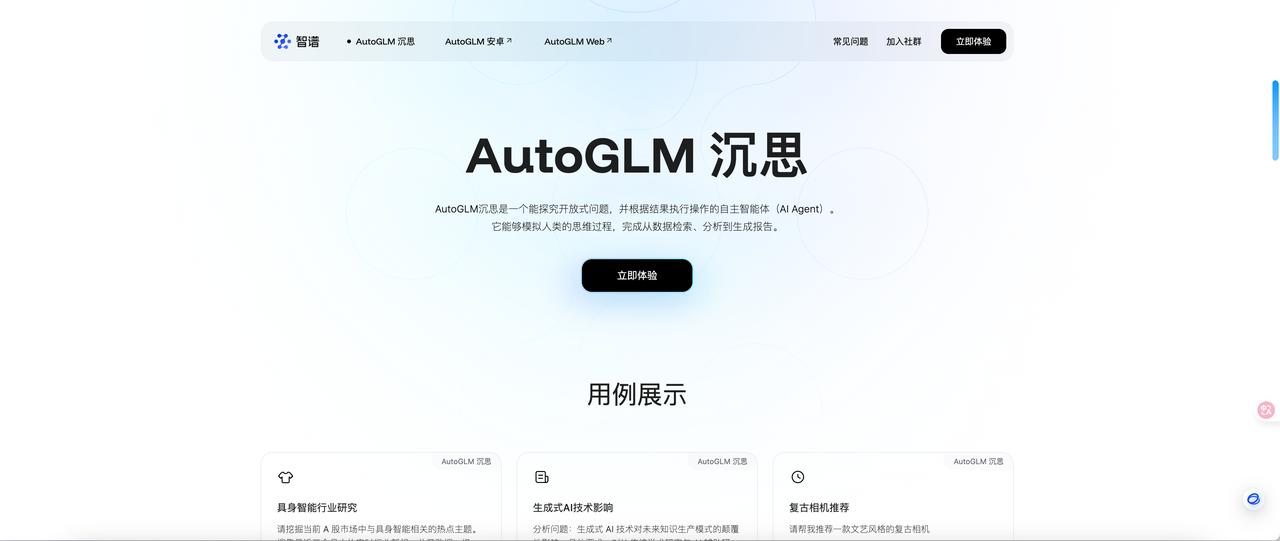
Positioning: A vertical domain agent platform based on the Zhipu GLM large model, focusing on scenarios like scientific research and law.
Core Capabilities:
- Academic knowledge base: Contains 20 million papers and patent data, supporting automatic literature review and analysis.
- Multimodal interaction: Supports PDF parsing and formula recognition, outputting LaTeX formatted documents.
Advantages: High precision in academic fields, suitable for universities and research institutions.
3. Nano AI Agent
Link: Nano AI Agent
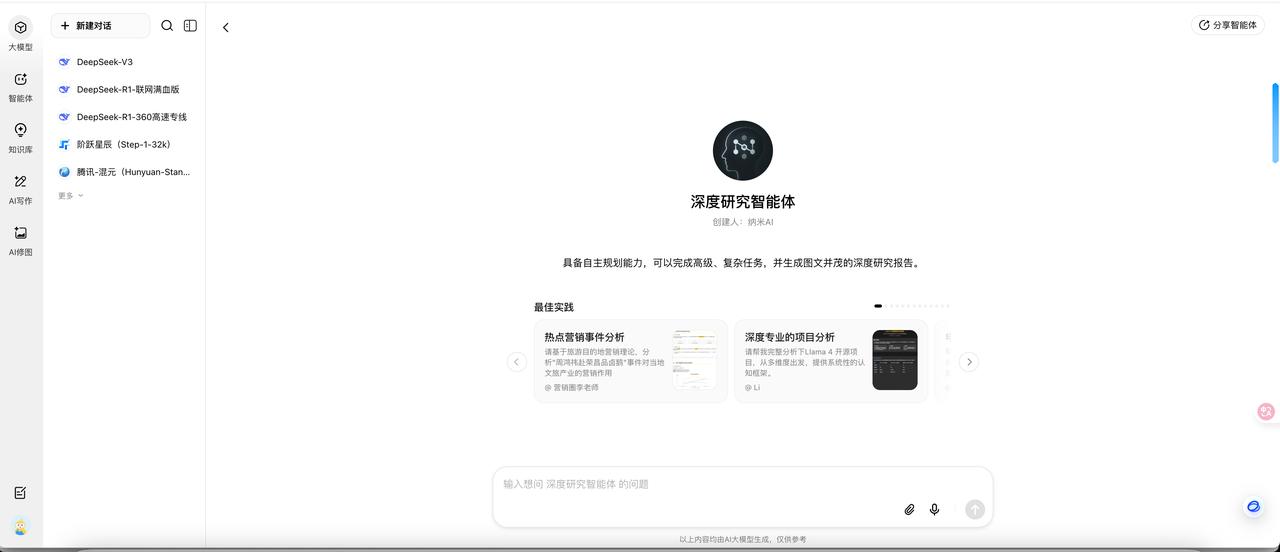
Positioning: The Nano AI Agent is an AI agent platform launched by the 360 Group, with its core product being the MCP universal toolbox, focusing on “zero-code construction of intelligent agents” and “open tool ecology,” showcasing significant differentiated advantages in technical architecture, application scenarios, and industry adaptability. Below is an analysis from three dimensions: technical features, application scenarios, and industry impact.
Core Capabilities:
- Quick setup in 5 minutes: Users can freely combine 360 self-developed tools (e.g., 360 Search, browser automation) and third-party tools (e.g., ArXiv academic search, Xiaohongshu data scraping) through a visual interface, with the system automatically generating task flows.
- Industry template library: Contains over 200 industry templates (e.g., financial risk control, HR recruitment, e-commerce operations), supporting one-click reuse. For example, selecting the “stock analysis assistant” template, the agent automatically calls the Tonghuashun API to fetch data → generates K-line charts → outputs risk warnings.
- Over 110 ready-to-use tools: Covering scenarios such as office collaboration, academic research, financial analysis, and life services, tool access requires no coding. For instance, if a user inputs “analyze the trends of the 2025 Shanghai Auto Show,” the agent can automatically call Gaode Maps to generate venue route maps → call web scraping tools to fetch media reports → call data visualization tools to generate comparison charts for new energy vehicles.
- Developer ecosystem: Supports user-defined tool access, allowing developers to easily configure local tools (e.g., Obsidian note retrieval) into MCP tools, forming a “thousand faces” intelligent agent ecology.
In-Depth Evaluation of Agents
1. Purpose: Webpage Generation Capability
Prompt: You are an experienced travel planner and front-end developer. Please generate a 5-day, 4-night travel plan for Dali and output it in a concise and aesthetically pleasing HTML webpage format.
Results:
1) Coze

Note: 1) There are serious logical issues, such as the hotel being a 7-hour walk from the ancient city, but the guide suggests, “After a short rest, stroll through the ancient city,” which is not common sense. Additionally, the accompanying image is of Jizu Ancient Town, not Dali Ancient City, and the Three Pagodas Reflection Park is also far from the hotel, not something that can be visited in one day. 2) The task was completed quickly, but not all requirements were met, and the generated webpage layout was overly simplistic and not usable as a travel guide.
2) Zhipu Thinking Auto GLM:

Note: 1) It only provided a downloadable PDF document and did not follow the final instruction to generate an HTML webpage link. 2) It did automatically open a new webpage to browse content from Xiaohongshu and other guides. 3) There were logical errors in the order of activities in Haidong and Dali.
3) Nano AI:
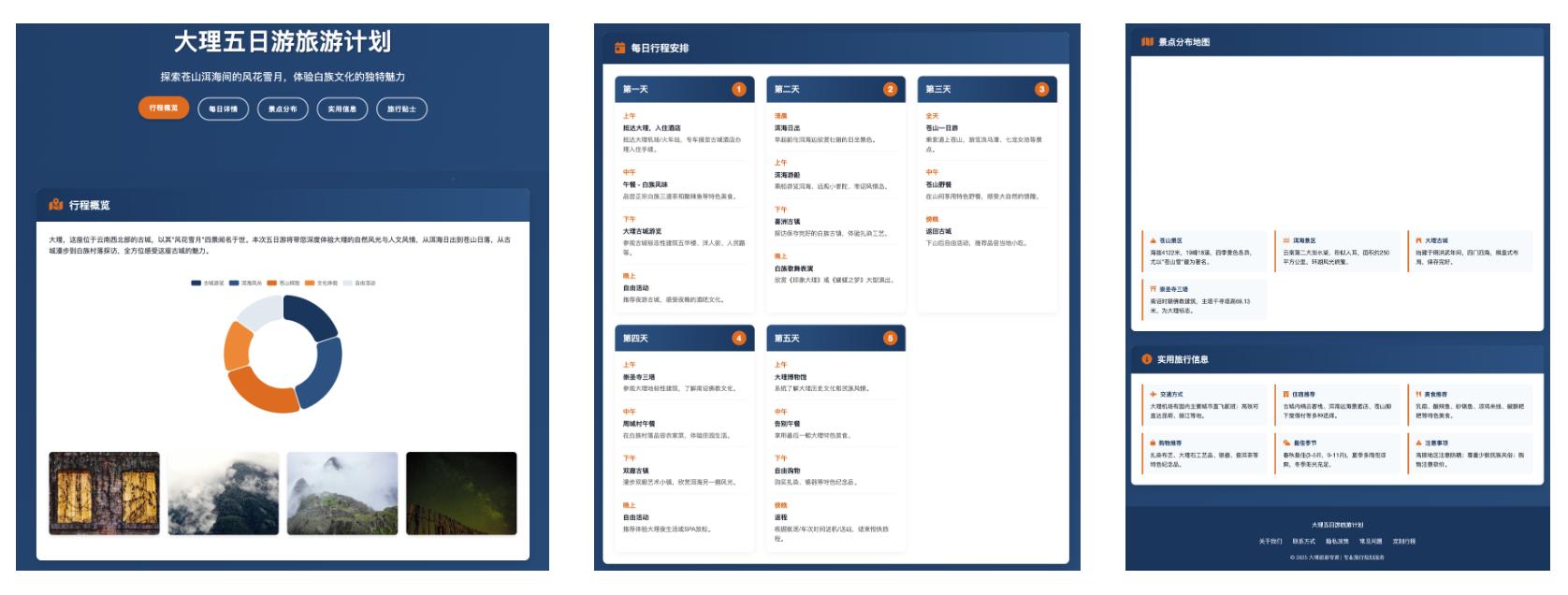
Note: 1) It completed the HTML output, taking about 20 minutes. 2) The overall UI is relatively aesthetically pleasing, but it is just a webpage display without interactivity, and the map was not displayed. 3) The generated content was too vague, lacking emphasis on the most beautiful scenic spots around Erhai Lake in Dali, with excessive focus on scenic area introductions, making it less useful for travel.
Overall Note: None of the three products provided satisfactory answers. Zhipu did not fulfill the instruction, Coze had many logical errors, and Nano AI had a slightly better interface but low content quality, providing little useful information.
2. Purpose: Game Development Capability
Prompt: You are a senior WebGL game developer. Please use Three.js to help me develop a “parkour mini-game” type of 3D web game and return the complete runnable HTML + JavaScript code.
Results:
1) Coze:

Completed the game development successfully and is usable, basically meeting expectations.
2) Zhipu Thinking Auto GLM:

Note: Only provided a rules document and running code, without giving a runnable file, feeling similar to an ordinary large model, not much like an agent.
3) Nano AI:
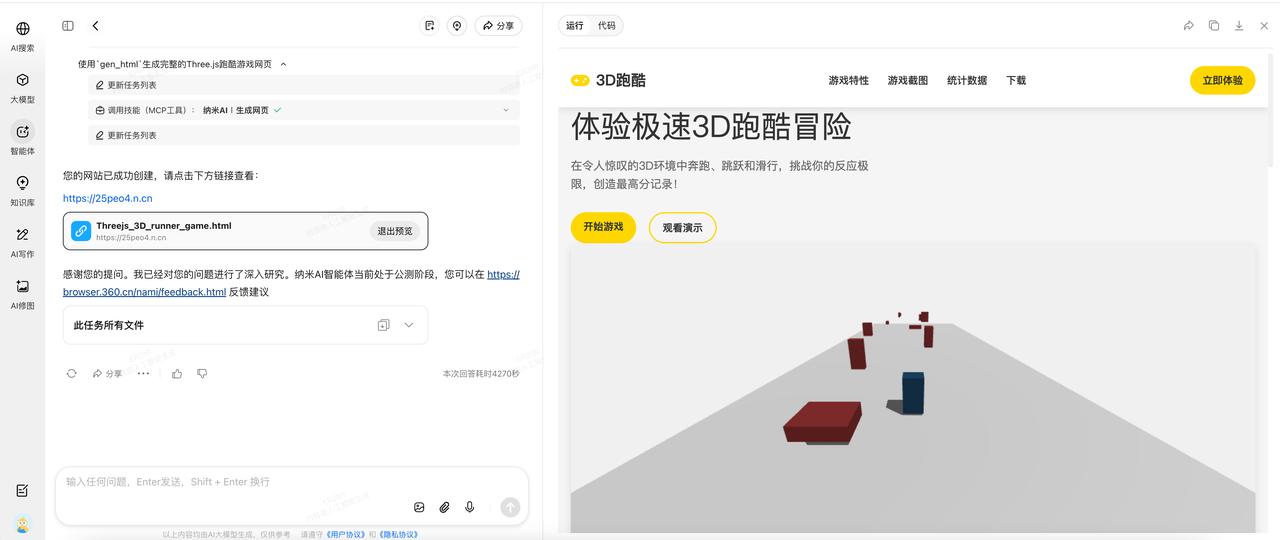
Completed the game development successfully and is usable, basically meeting expectations.
Overall Note: Among the three products, only Zhipu Thinking Auto GLM did not generate a web-based mini-game, only providing code, while the other two agents basically met expectations.
3. Purpose: Information Retrieval Capability
Prompt: You are a professional health and fitness content editor. Please collect and compile a complete “30-day weight loss plan” with images and text suitable for ordinary people to reference at home. Please combine authoritative health information and popular trends, returning it in a structured graphic format and outputting it in PDF format.
Results:
1) Coze:

Note: Basically meets the requirements but lacks images, only text, and ultimately generated a PDF document.
2) Zhipu Thinking Auto GLM:

Note: Also basically meets the requirements, did not generate images, and ultimately provided a PDF document.
3) Nano AI:
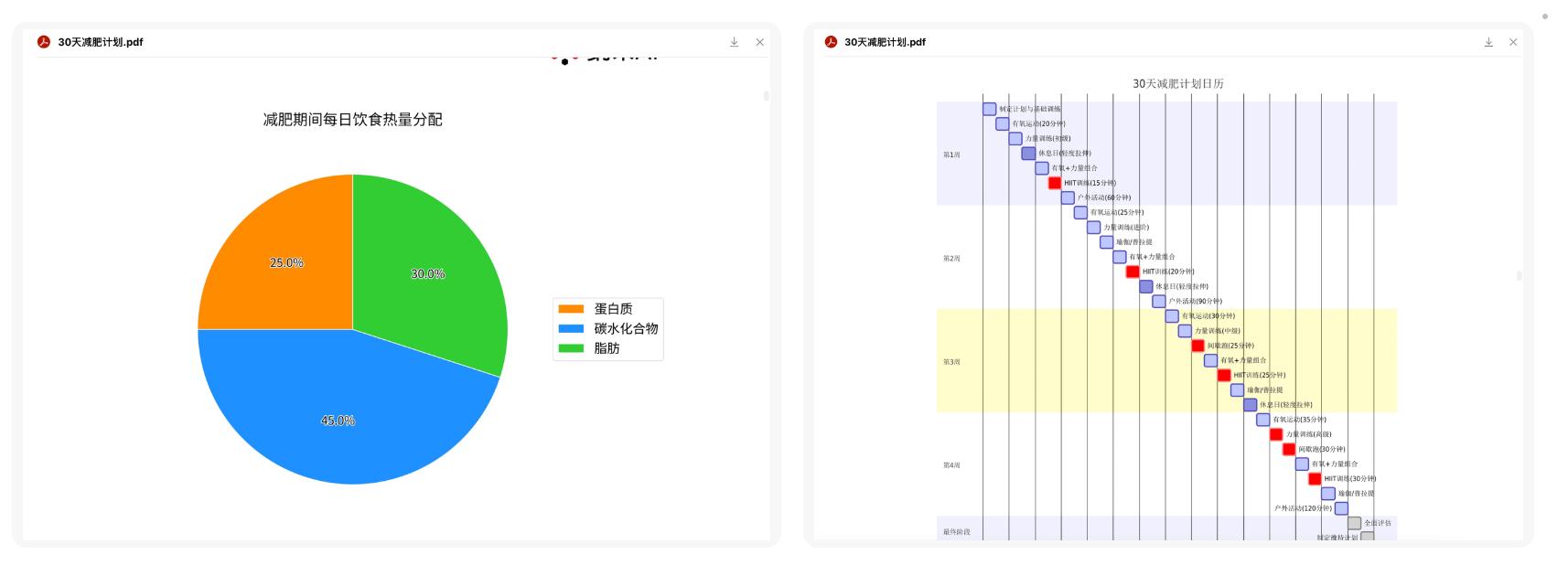
Note: Basically meets the requirements, with goals, diet, exercise, and plans, including illustrations, and generated a PDF document.
Overall Note: Among the three products, only Nano AI provided graphic expression, while the other two products only produced text-based PDFs.
Conclusion
In this evaluation, we conducted an in-depth comparison of Zhipu Thinking Auto GLM, Coze, and Nano AI across dimensions such as webpage generation capability, game generation capability, and information retrieval capability. It is evident that each has its own advantages, but there are also issues that need improvement. As large models and agent technologies continue to evolve, we have reason to believe that different types of agents will grow according to user needs and ultimately move towards integration. The choice of which platform to use depends not on which is stronger, but on what your task scenario truly requires.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.