
Recently, APPSO mentioned that large models are about to face the most challenging month in history, and this has come to pass.
Claude Opus 4.6 has unfortunately become a backdrop, being surpassed twice in one day.
In the morning, Anthropic released the Claude Mythos Preview, scoring 77.8% on SWE-bench Pro, leaving Opus 4.6’s 57.3% behind. This score indicates it can identify and fix high-difficulty engineering bugs in real GitHub repositories, surpassing most human programmers.
However, the Mythos Preview is not yet available to the general public. Meanwhile, another model has emerged that surpasses Opus 4.6—Zhipu has open-sourced GLM-5.1.

GLM-5.1 scored 58.4% on SWE-bench Pro, exceeding Opus 4.6’s 57.3% and GPT-5.4’s 57.7%. HuggingFace CEO Clement Delangue congratulated the release on Twitter, stating: “The best-performing model on SWE-Bench Pro is now open-sourced on HuggingFace! Welcome GLM 5.1!”
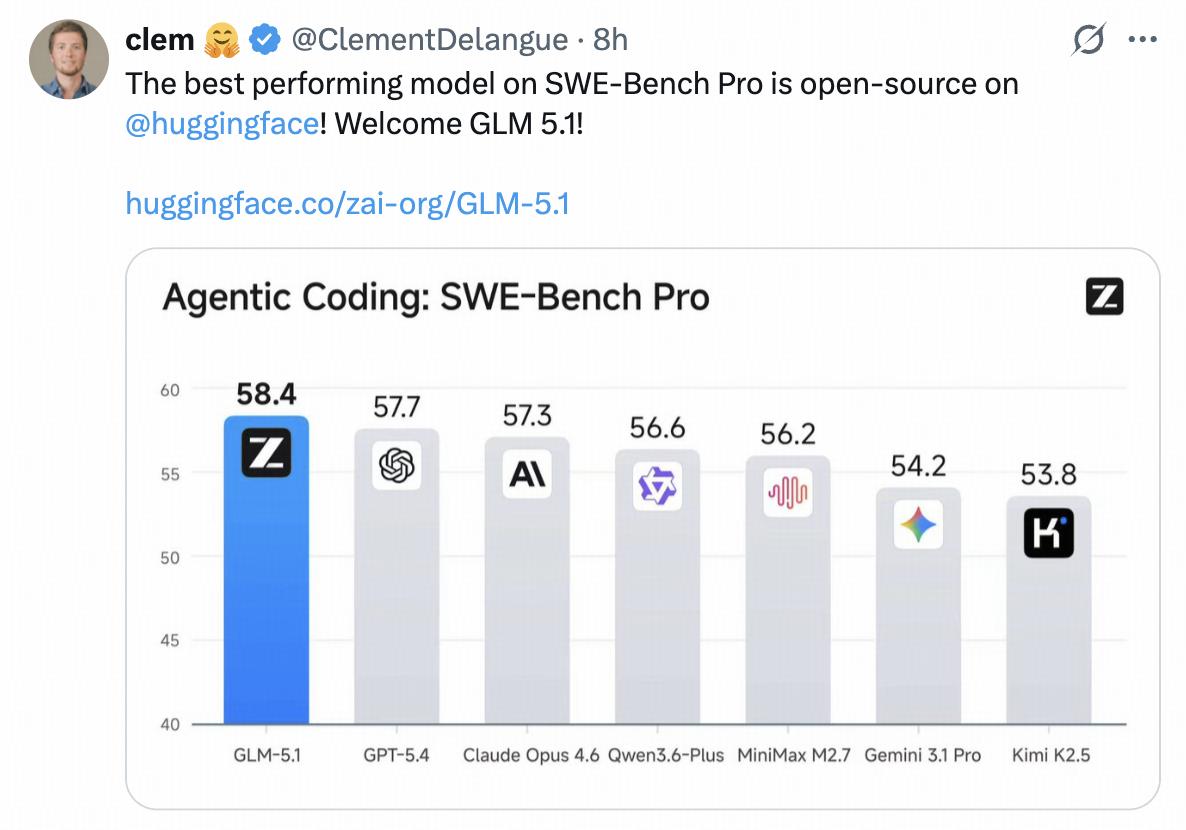
Ranked third globally and first in open-source, GLM-5.1 has emerged as a leading domestic model, even without the anticipated DeepSeek V4.
My initial reaction was that we are witnessing another round of the large model “ranking frenzy,” where each release claims “epic progress,” and models briefly dominate the leaderboard. What makes this time different?
After reviewing the technical details and experiences with GLM-5.1, APPSO provides insights into the model’s capabilities.
From 20 Steps to 1700 Steps, Continuous Operation for 8 Hours
What surprised me most about GLM-5.1 is not its score, but its operational duration.
Zhipu has a case that left a strong impression on me. It built a Linux desktop system from scratch in 8 hours. This was not just writing a few demo files; it involved designing architecture, writing code, running tests, and fixing bugs, completing over 1200 steps to produce a fully functional Linux desktop system.
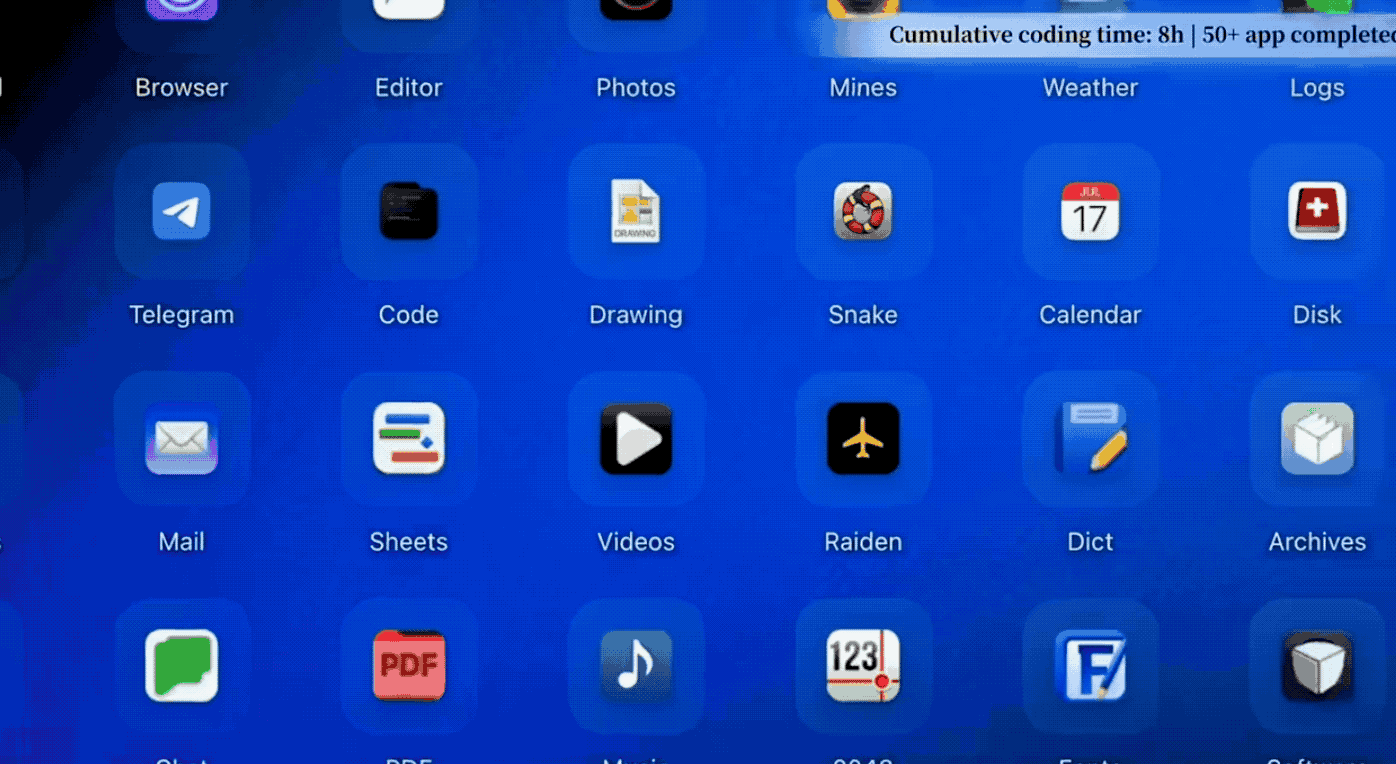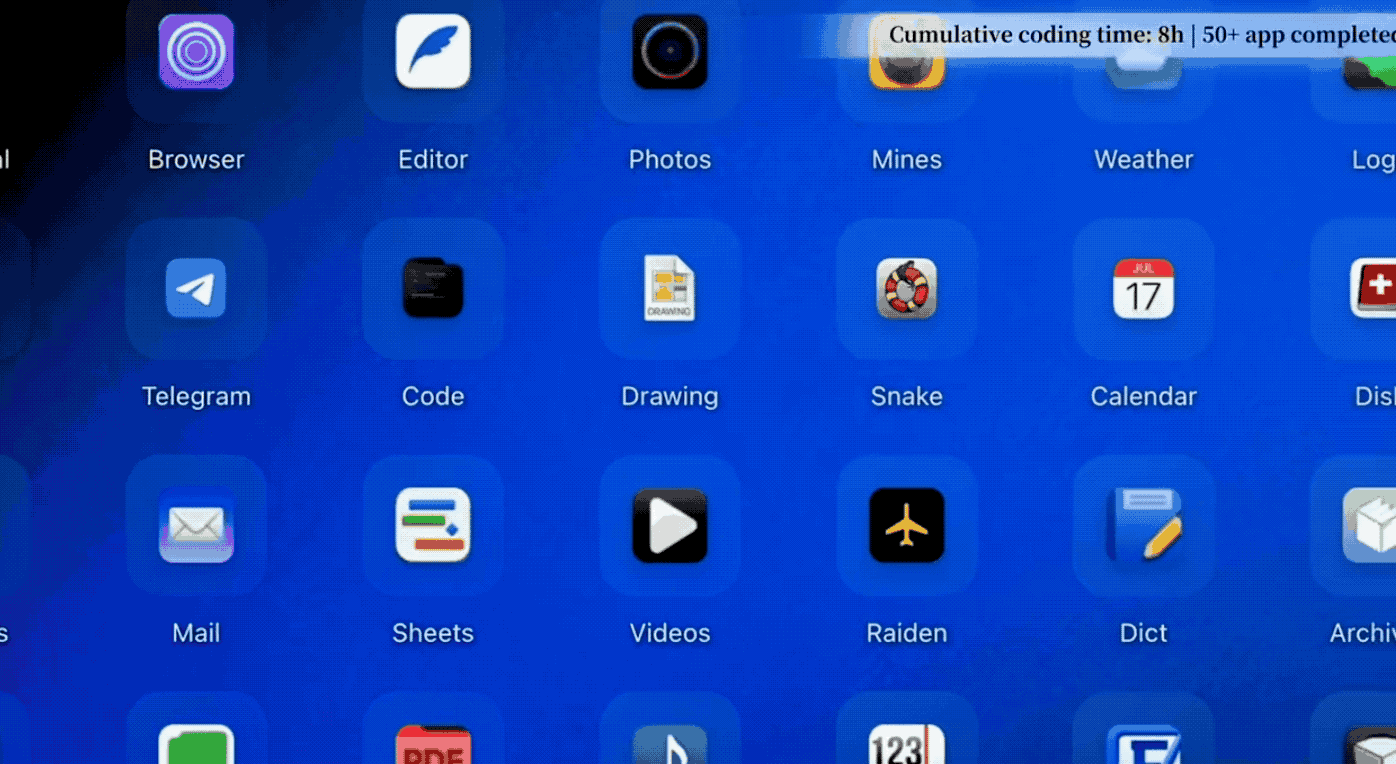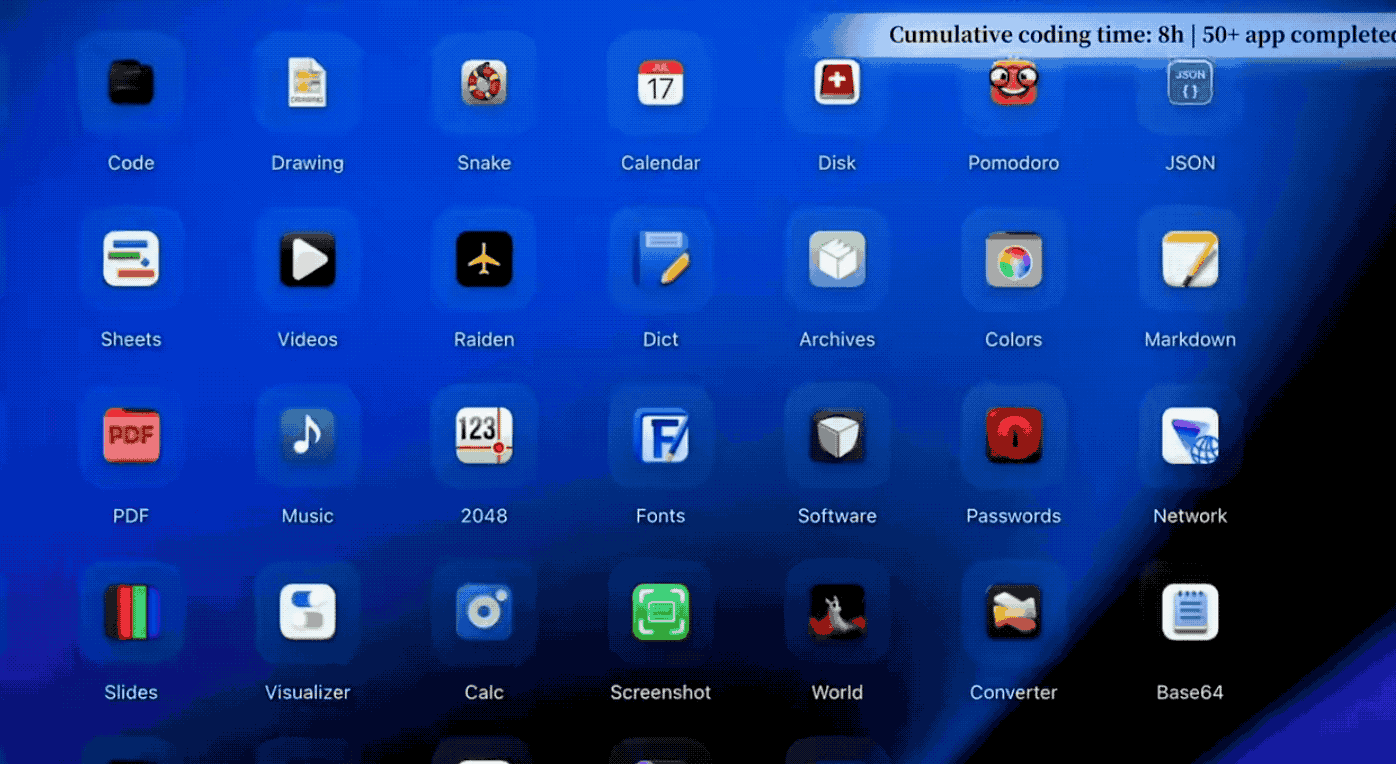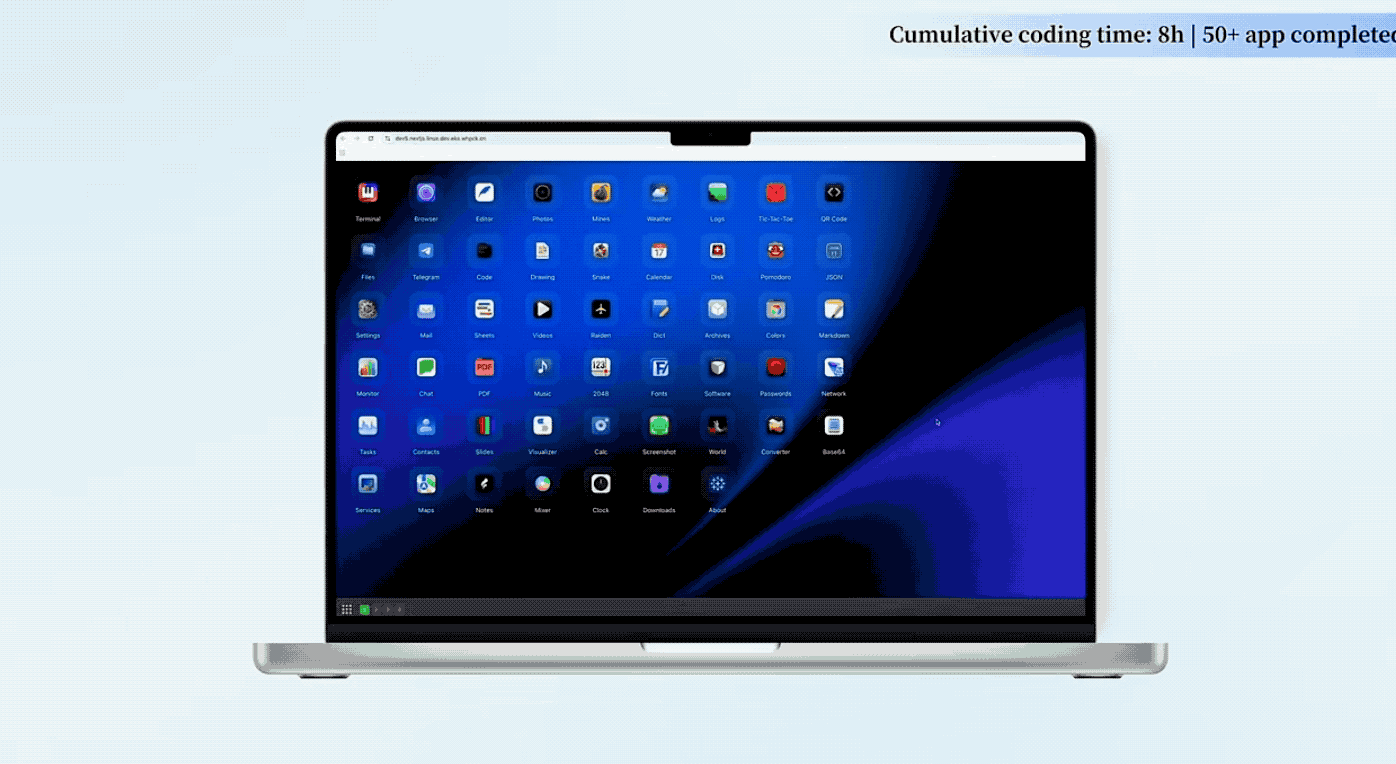
This included a complete desktop, window manager, status bar, applications, VPN manager, Chinese font support, and a game library, all in a 4.8MB package. This is equivalent to a week’s work for a four-person team.
No one was involved in testing or code review throughout the process. GLM-5.1 even wrote its own regression tests, which it successfully executed.
A programmer on Zhihu, Toyama nao, conducted a more rigorous test. He tasked GLM-5.1 with three projects: developing an OpenGL renderer for macOS in Swift, creating a fully functional chat application in Flutter while simultaneously developing the backend in Golang, and building a web-based video editing application with a selected tech stack. Each project underwent 10-12 rounds of prompts, with each round consisting of 1500-2000 words.
As a result, GLM-5.1 became the first domestic model to pass all of Toyama nao’s test projects and the first to officially surpass Sonnet 4.5 Thinking.
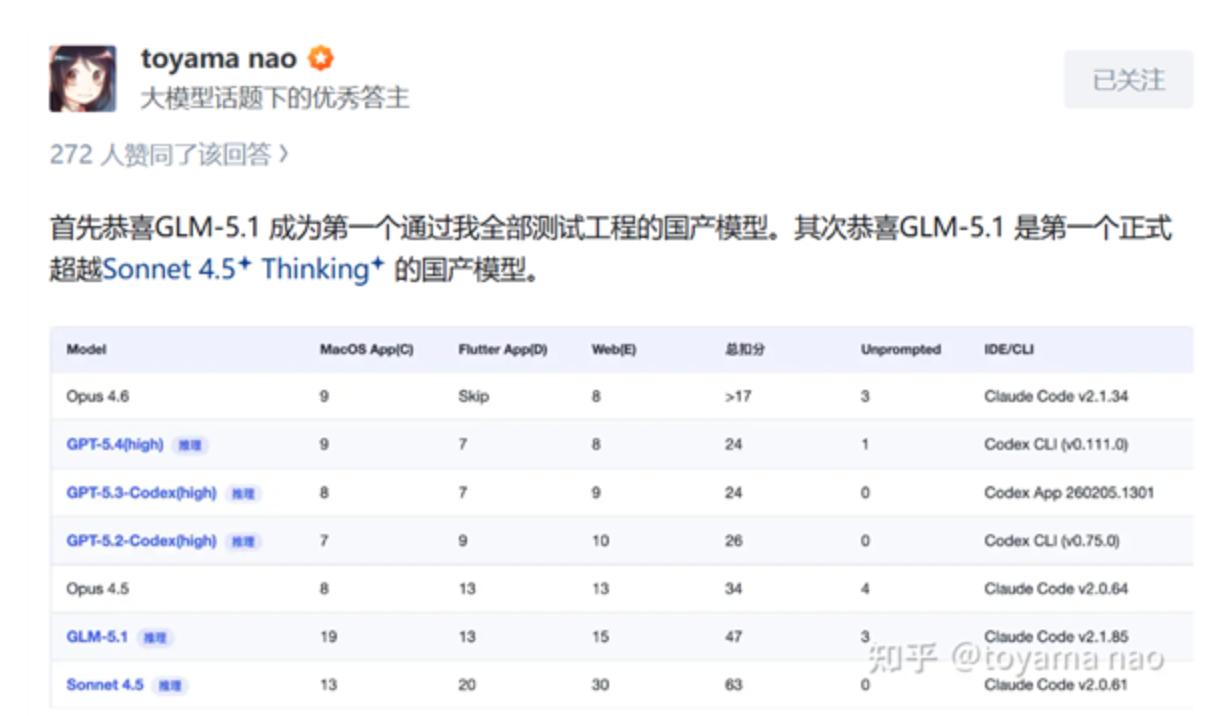
His evaluation was: “GLM-5.1 significantly expands the adaptability of programming, no longer just a front-end warrior or a one-shot wonder; it can serve as a primary programming force under complex conditions.” However, he also pointed out issues: “It tends to hallucinate with long contexts; if it struggles with a problem after two rounds of revisions, don’t expect it to improve—just start over.”
At the end of last year, AI models could only complete about 20 steps. GLM-5.1 can now accomplish 1700 steps, marking a watershed moment for models to genuinely “work independently.”
Zhipu explained the key breakthroughs in their technical report: previous models, including GLM-5, would quickly reach a bottleneck after initial gains. They repeatedly attempted known optimization methods but could not switch strategies when one path failed.
The training goal of GLM-5.1 was to break through this bottleneck, enabling the model to perform incremental tuning within a fixed strategy, actively analyzing benchmark logs to identify current bottlenecks and then switching to structurally different solutions.
An example of vector database optimization illustrates this “stair-step” optimization trajectory. GLM-5.1 underwent 655 iterations, increasing query throughput from 3108 QPS to 21472 QPS, achieving a 6.9-fold improvement.
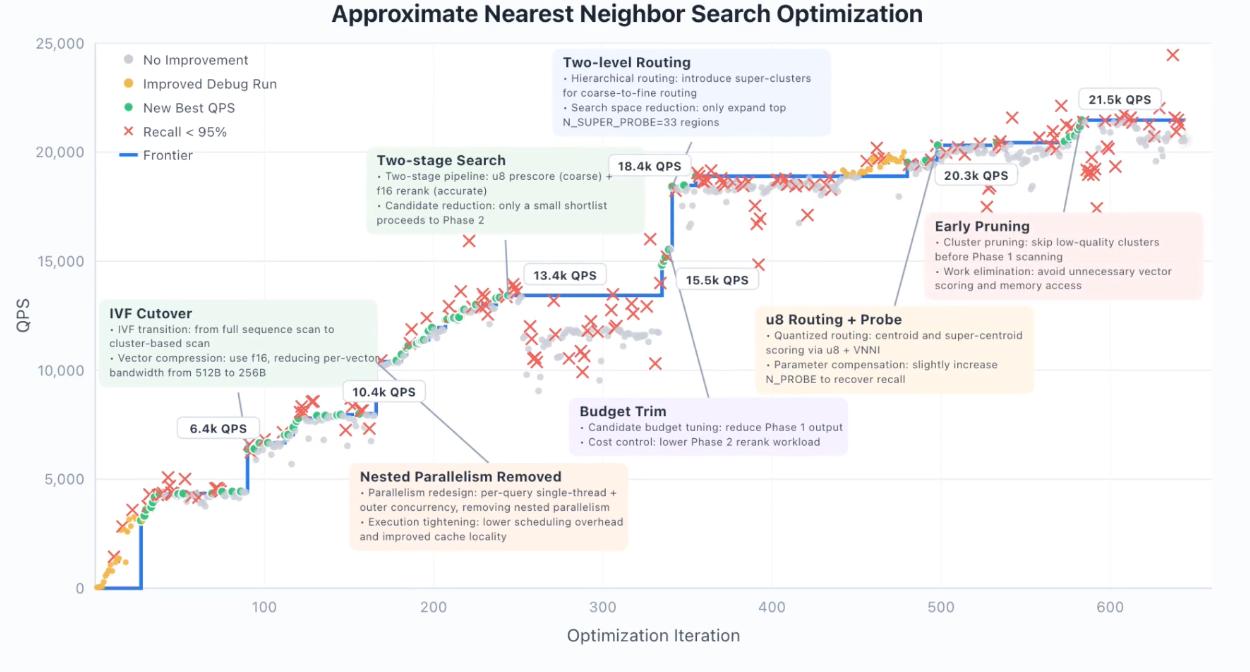
During this process, the model autonomously completed the entire optimization chain, transitioning from full library scanning to IVF bucket recall, introducing half-precision compression, adding quantization coarse ranking, implementing two-level routing, and performing early pruning. Each leap was accompanied by a temporary decrease in recall, as the model would break constraints while exploring new directions, only to adjust back afterward. This “break-fix” cycle is a hallmark of effective optimization.
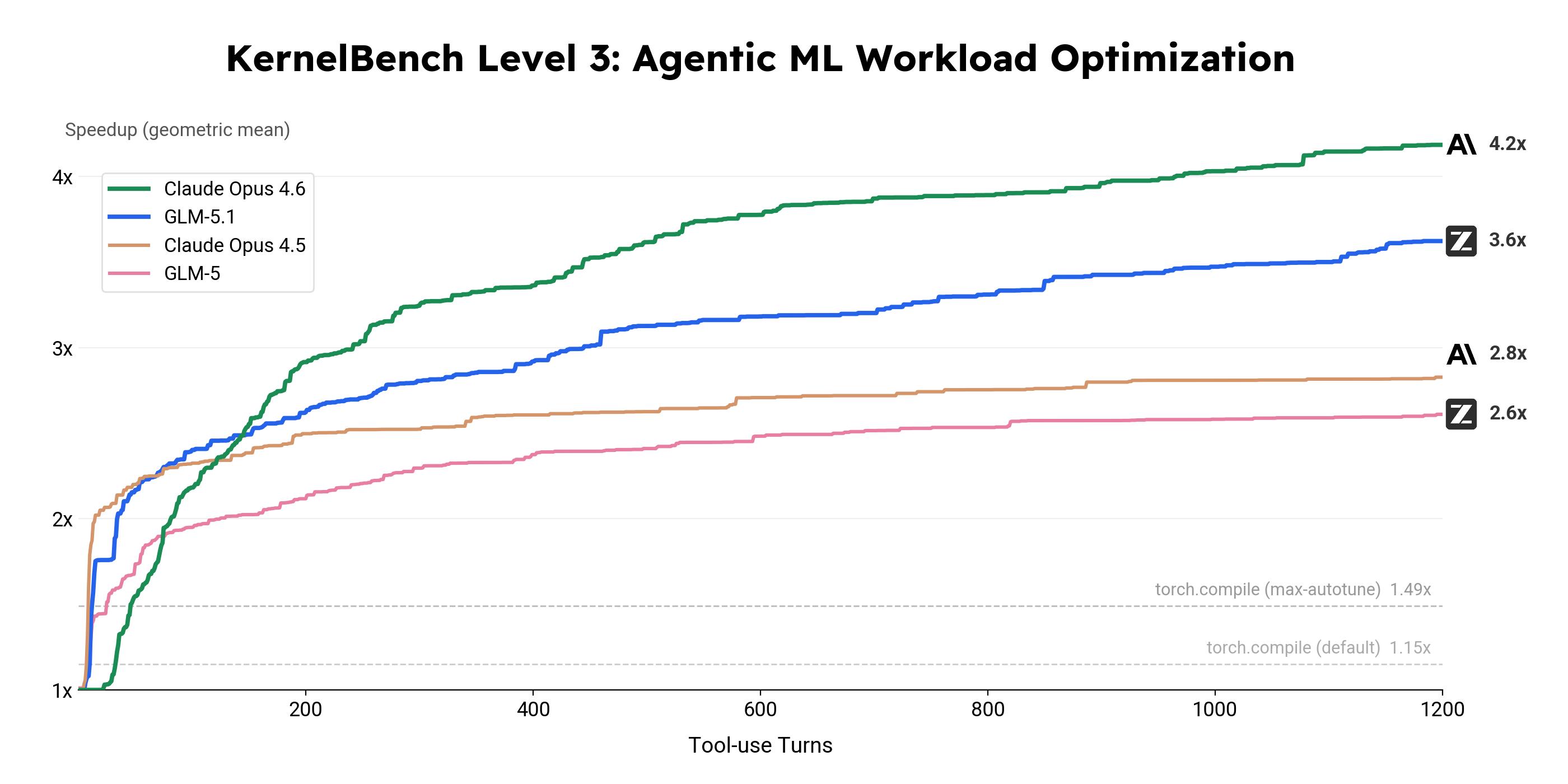
On the KernelBench Level 3 optimization benchmark, GLM-5.1 performed over 24 hours of uninterrupted iterations on 50 real machine learning computational loads, achieving a geometric mean speedup of 3.6 times, significantly surpassing the 1.49 times of torch.compile max-autotune mode. The model autonomously wrote custom Triton Kernels and CUDA Kernels, utilizing cuBLASLt epilogue fusion and implementing shared memory tiling and CUDA Graph optimizations, covering the complete tech stack from high-level operator fusion to micro-architecture tuning.
Another interesting test was Vending Bench 2. This benchmark required the model to simulate running a vending machine business for a year, necessitating long-term planning and resource management. GLM-5.1 ultimately achieved a balance of $4,432, ranking first among open-source models and approaching the level of Claude Opus 4.5.
744B Parameters, No NVIDIA Chips, 97% Cost Reduction
The technical specifications of GLM-5.1 are worth noting: it is a mixed expert model (MoE) with 744 billion parameters, activating 40 billion parameters per token, trained on 28.5 trillion tokens of data, and incorporates DeepSeek Sparse Attention (DSA) to reduce deployment costs while maintaining long context capabilities. It features a 200K context window and a maximum output of 131,072 tokens.
More importantly, the entire model was trained using Huawei’s Ascend 910B chips, with no NVIDIA GPUs involved. Despite being constrained by computing power, the domestic model has still achieved third place globally and first in open-source.
Developer Beau Johnson switched the model behind his deployed OpenClaw from Claude Opus 4.6 to GLM-5.1, experiencing no difference in performance, but reducing costs from $1,000 to about $30, a 97% decrease. The input cost of GLM-5.1 is 1/5 that of Claude Opus, and the output cost is 1/8. In simple terms: near Opus’s capabilities at 20% of the price.
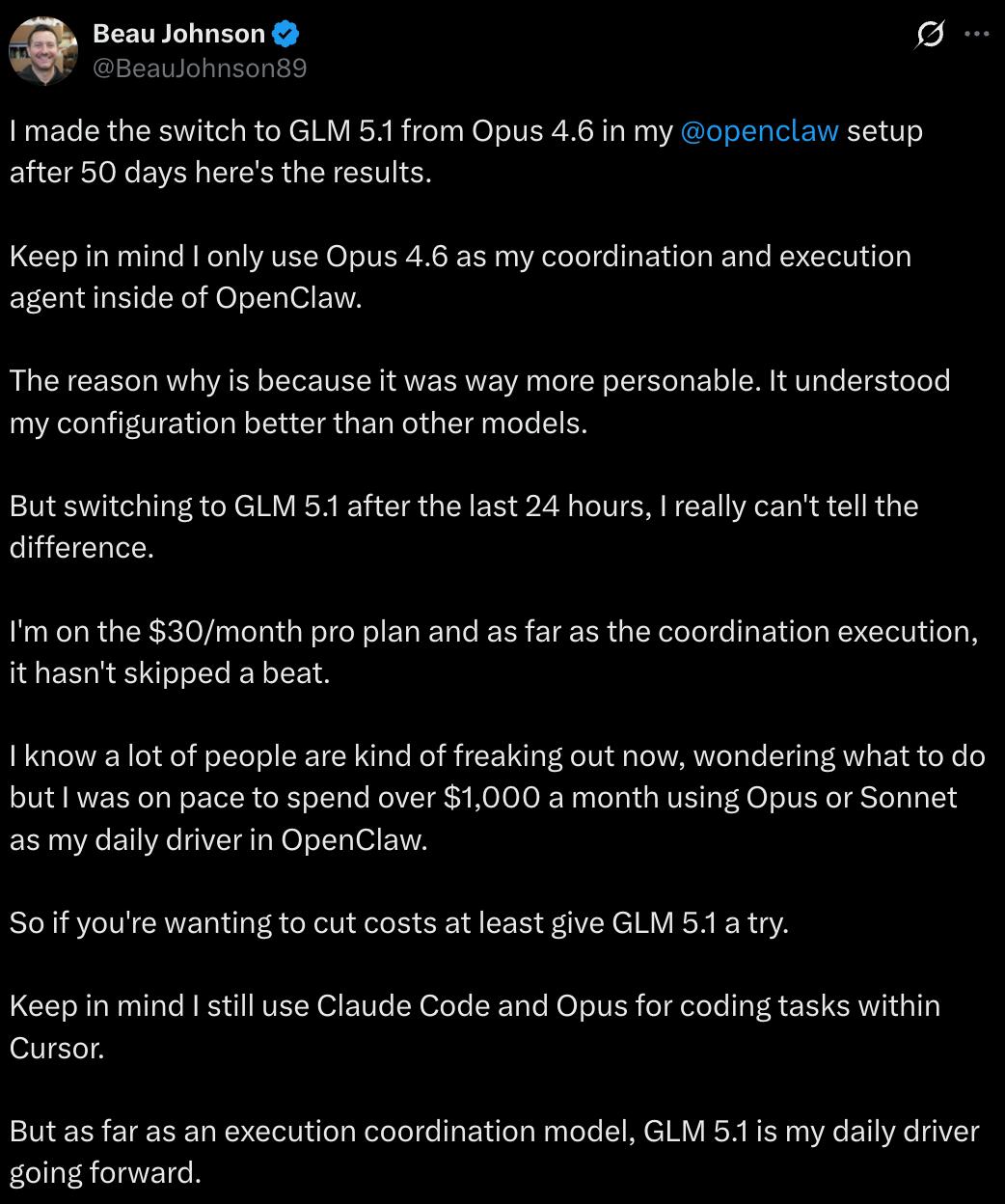
Moreover, GLM-5.1 is open-source, licensed under the MIT License, one of the most permissive open-source licenses. You can modify it, use it commercially, and do anything with it. It supports mainstream inference frameworks like vLLM, SGLang, and xLLM, allowing for direct local deployment.
Of course, GLM-5.1 is not without room for improvement. Some developers have reported that its inference speed is only 44.3 tokens/second, offering no significant advantage over similar products. Complex tasks can even take an hour to start, and even though the Pro package limits are 15 times that of Claude, it may still be insufficient.
These issues are real. GLM-5.1 is not perfect, but this does not prevent it from being a milestone.
The significance of GLM-5.1 lies not in how much stronger it is than Opus 4.6, but in proving that even under constraints of computing power, domestic models can still achieve first place in open-source. Furthermore, it is open-source, allowing anyone to use and modify it.
Your 8 hours of sleep can now be 8 hours of AI work. And this AI is open-source, domestically produced, and accessible to everyone.
Experience Methods
- Official API Access
– BigModel Open Platform:
https://docs.bigmodel.cn/cn/guide/models/text/glm-5.1
– Z.ai:
https://docs.z.ai/guides/llm/glm-5.1
-
Product Experience – GLM-5.1 is coming to Z.ai:
https://chat.z.ai -
Open-source Links
– GitHub:
https://github.com/zai-org/GLM-5
– Hugging Face:
https://huggingface.co/zai-org/GLM-5.1
– ModelScope:
https://modelscope.cn/models/ZhipuAI/GLM-5.1
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.