
DeepSeek V4 has finally been released after a long wait, fortunately not during the May Day holiday.
The new model has a clear positioning, emphasizing coding capabilities and ultra-long context processing, which aligns with current urgent needs.
In China, there are already several models with million-token contexts, but they generally use linear attention models. In contrast, DeepSeek V4 relies on a sparse attention mechanism, which reduces the attention connection strength, while the former weakens the attention focus range.
In practical terms, these distinctions may not be significant; let’s look at the results. The focus of this evaluation will be on these two dimensions, tested on both the web interface and Claude Code.
Context Length Effectiveness
The industry generally assumes that only about a quarter of the million-token context is useful, with half being considered exceptional.
The easiest way to test context effectiveness is through a “needle in a haystack” approach, searching for target markers within a large volume of text.
A Chinese novel of approximately one million characters, totaling about 900 pages, was selected. A marker “deepseekv4” was added at the beginning and randomly inserted every 100 pages, totaling 10 markers.
In expert mode on the web interface, the novel’s txt document was sent to DeepSeek with the query: “How many ‘deepseekv4’ markers are in this document, and what is the position of the 5th one?”
DeepSeek quickly provided an answer, but it was clear that “Total 5” was incorrect. Apart from the first marker, which was easy to find, the descriptions of the other markers were inaccurate, including the third marker’s position, which was actually the fourth marker’s position, and others that did not exist.

The answer of “5” was related to my question, so I rephrased it to ask for the third marker. This time, DeepSeek reported only 2 markers instead of 5.

This result was not surprising, as the context was filled to capacity.
Next, we halved the text length to see the effect. After halving, the number of markers remained 5, and DeepSeek was asked to identify the position of the third marker.
DeepSeek did not accurately state the total number of markers but correctly identified the position of the third marker.

However, when asked to find the fourth marker, it identified the fifth marker instead.

Overall, the results were not satisfactory, as DeepSeek V4’s context effectiveness could not be deemed to reach half.
We halved the text again, reducing the total markers to 3, and asked DeepSeek to find the position of the second marker. This time, DeepSeek accurately counted the total number of markers but confused the third marker with the second.
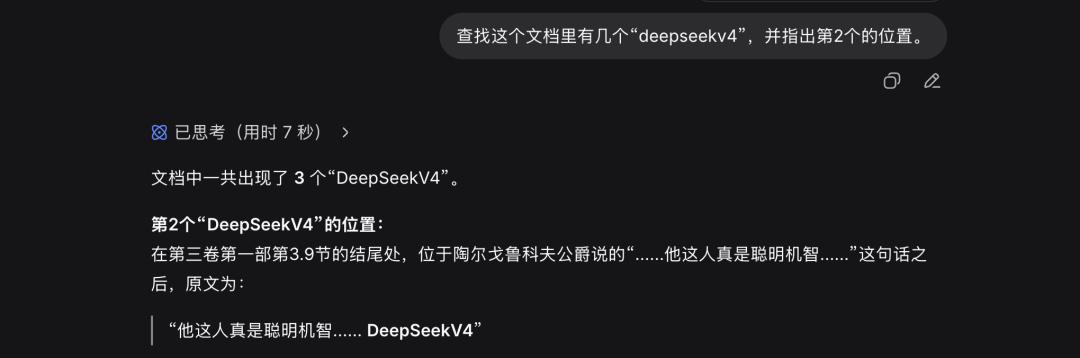
In the final reduction, the total markers were down to 2, and DeepSeek was asked to identify the position of the second marker. This time, DeepSeek succeeded in both tasks.
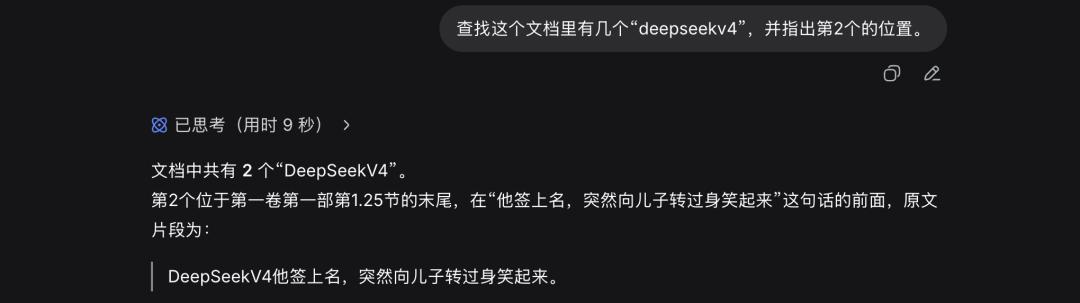
However, the problem had been overly simplified, as the remaining two markers were at the beginning and end, making them easier to find. Therefore, I randomly inserted another marker in the middle to see if DeepSeek could handle this, but it failed again, claiming there was only one marker when there were actually 3.
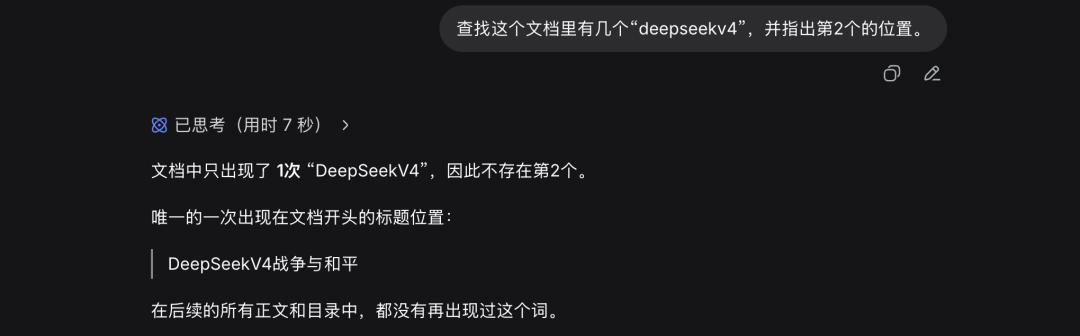
The final text was about 100,000 words, equivalent to around 100,000 tokens, only one-tenth of the total length.
At this point, there was no clear boundary for the effective context of DeepSeek V4. In practical scenarios, writing a simple web page can easily reach 50,000 to 80,000 tokens. Can DeepSeek V4 maintain a low hallucination rate in practice?
Let’s directly test it. Using a previously tested web-based Excel example with GPT-5 and Gemini 3 Pro to increase the difficulty.
The first version provided by DeepSeek encountered numerous errors, and just as I was about to click on a cell to input, the web page went blank.
Due to the numerous errors, I asked DeepSeek to check and fix them, but it returned a blank screen.
I then lowered the difficulty by asking it to create a 2048 game, which it completed successfully.
Next, I upped the challenge by asking it to build a 3D LEGO software. This time it succeeded on the first try, implementing basic functions, but it did not allow for free selection of parts, only using one type of rectangular brick.
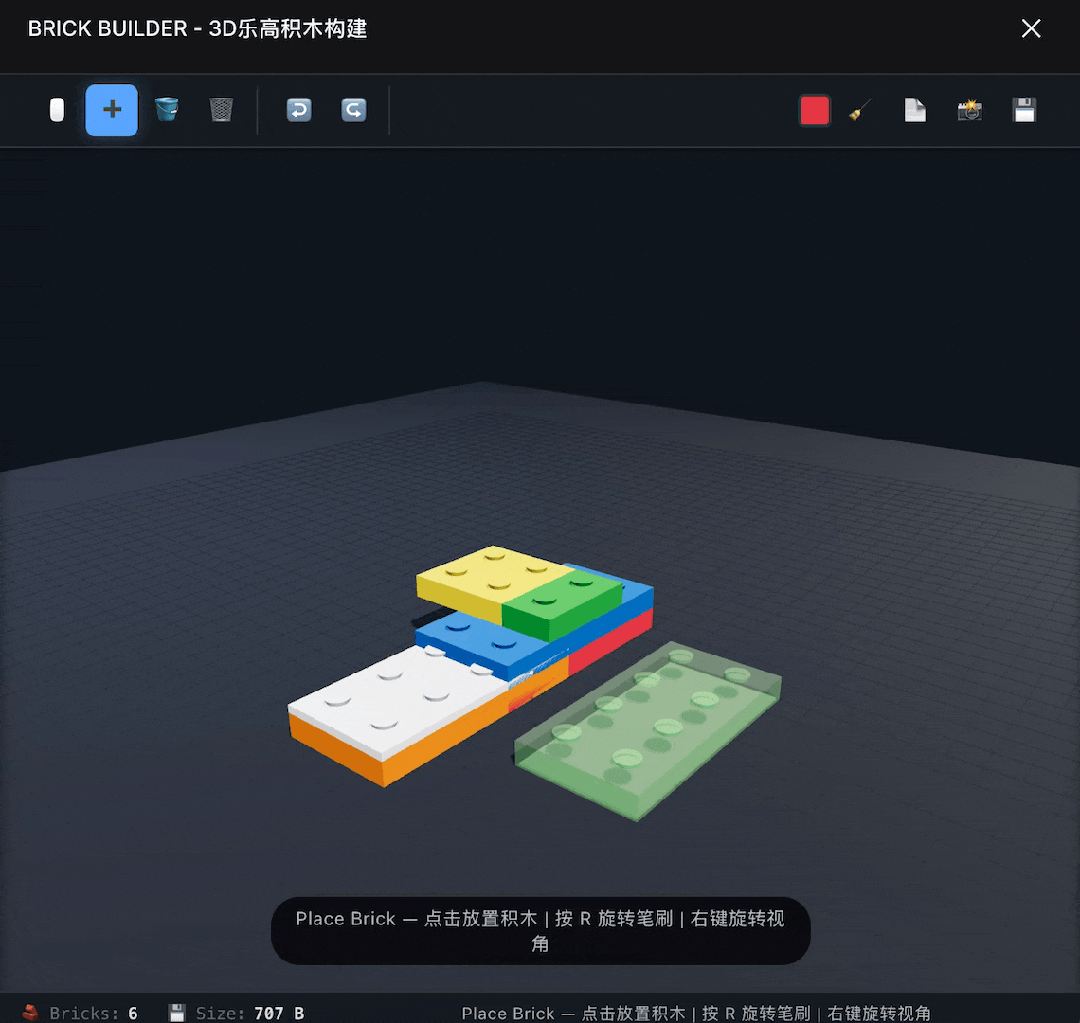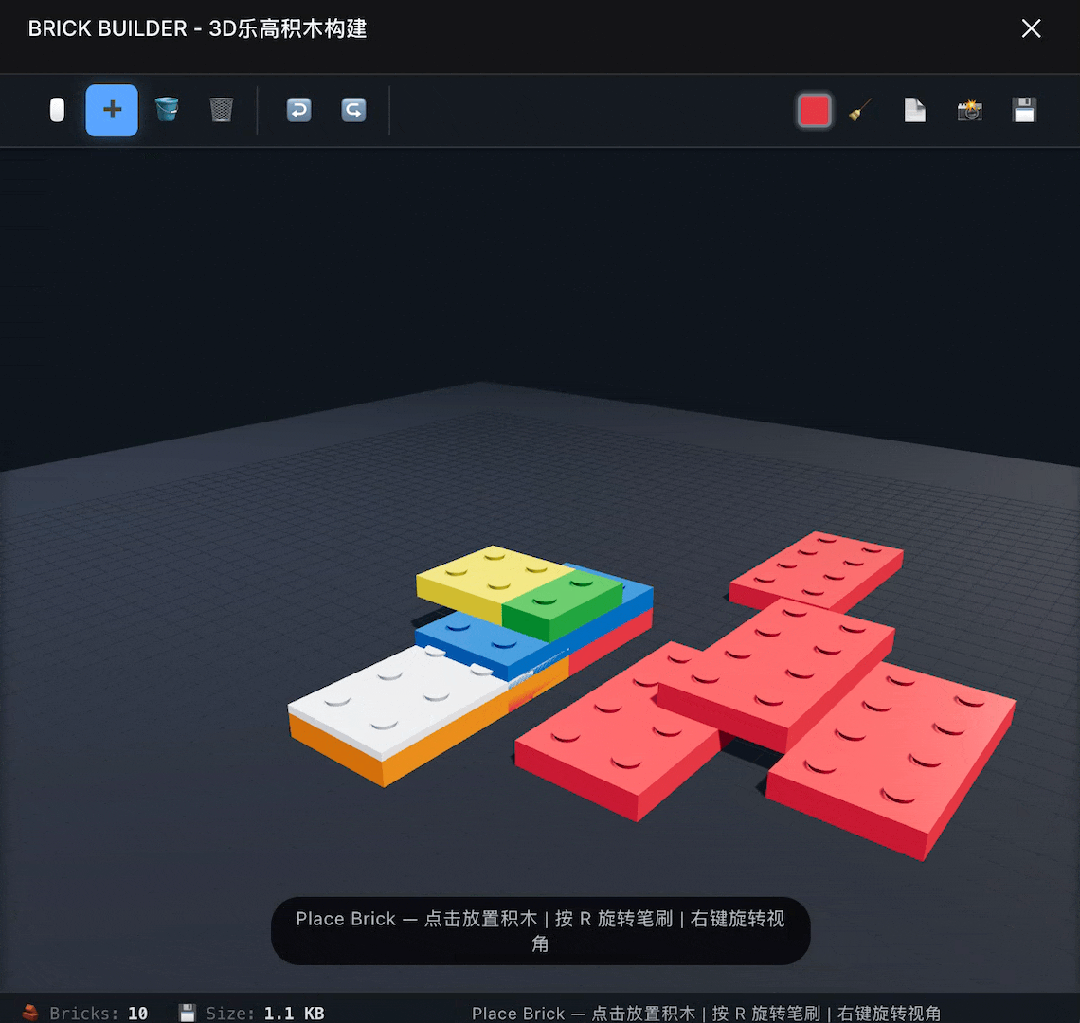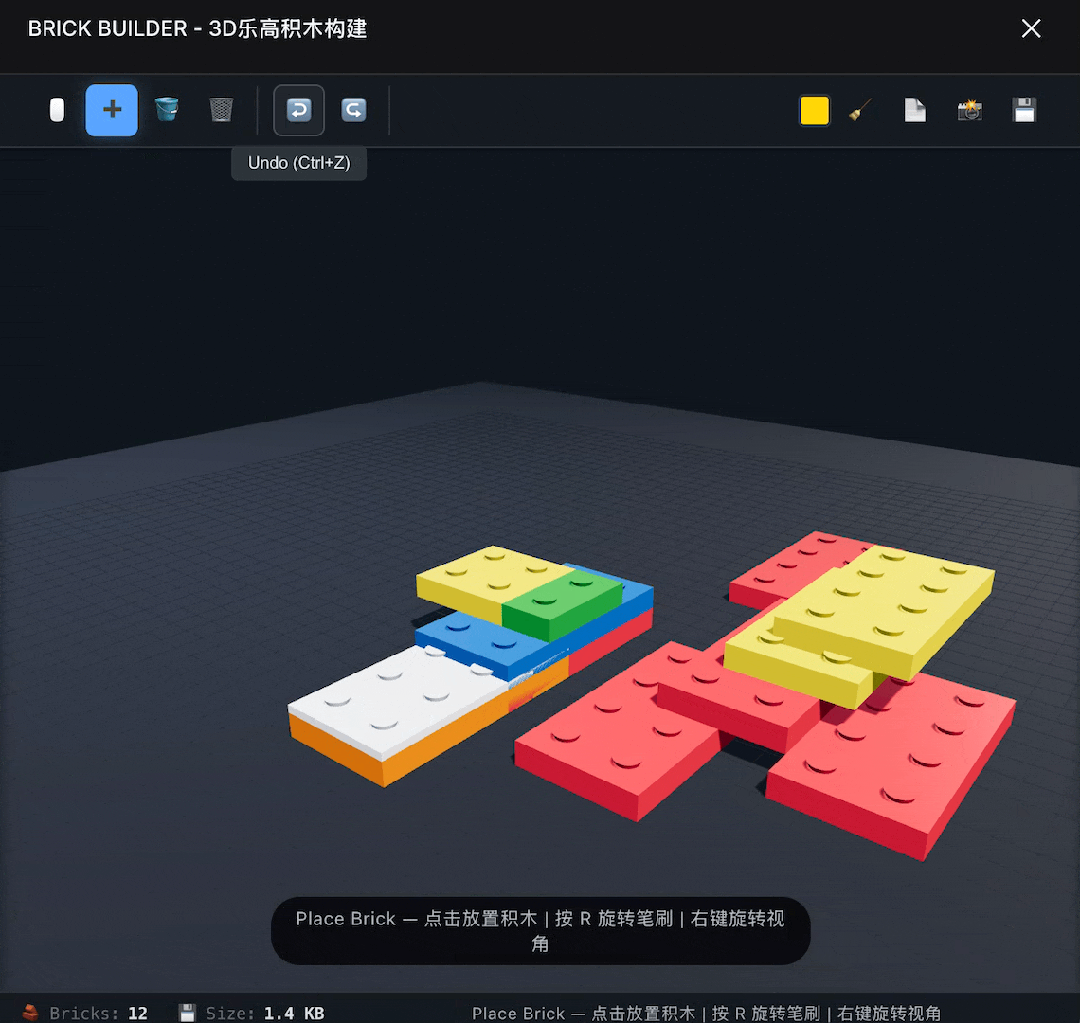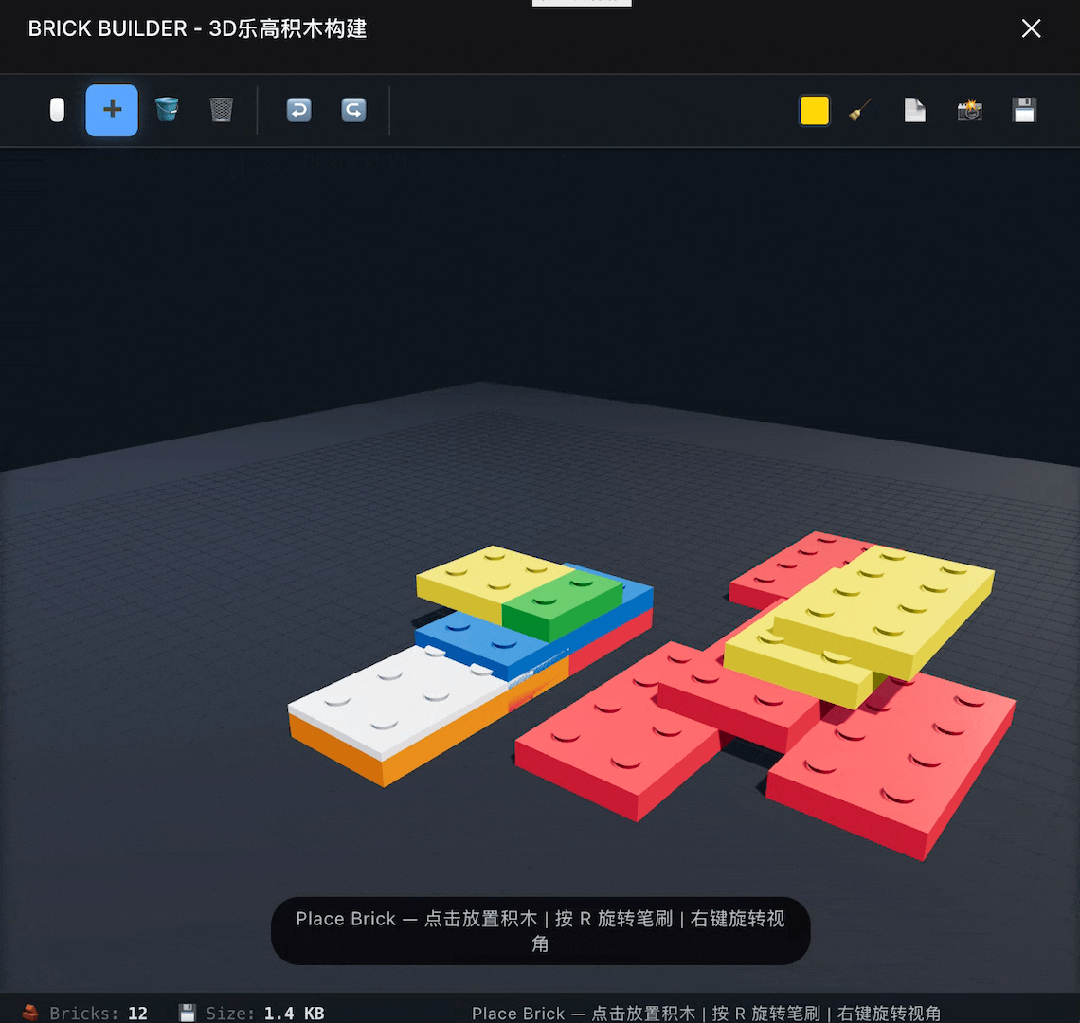
After prompting DeepSeek to fix this issue, it provided a modified version with no changes.
I lowered the difficulty again, asking it to generate an animation of a tree growing. According to demonstrations on Twitter, Qwen 3.6 and Gemma 4 could complete this task well.
Prompt:
Create an animation of a tree growing from the bottom center of the screen in a full-screen HTML file (without using any libraries). The trunk grows upward first, then branches split recursively with slight randomness in angle and length. Each generation of branches should be thinner and lighter in color. When the branches reach their final size, soft green circles should be added at the tips as leaves. The tree should take about 15 seconds to fully grow. Use warm brown for the trunk and various greens for the leaves, with a soft sky blue gradient background.

The result was quite good; DeepSeek V4 not only completed the task but also produced an aesthetically pleasing final image.
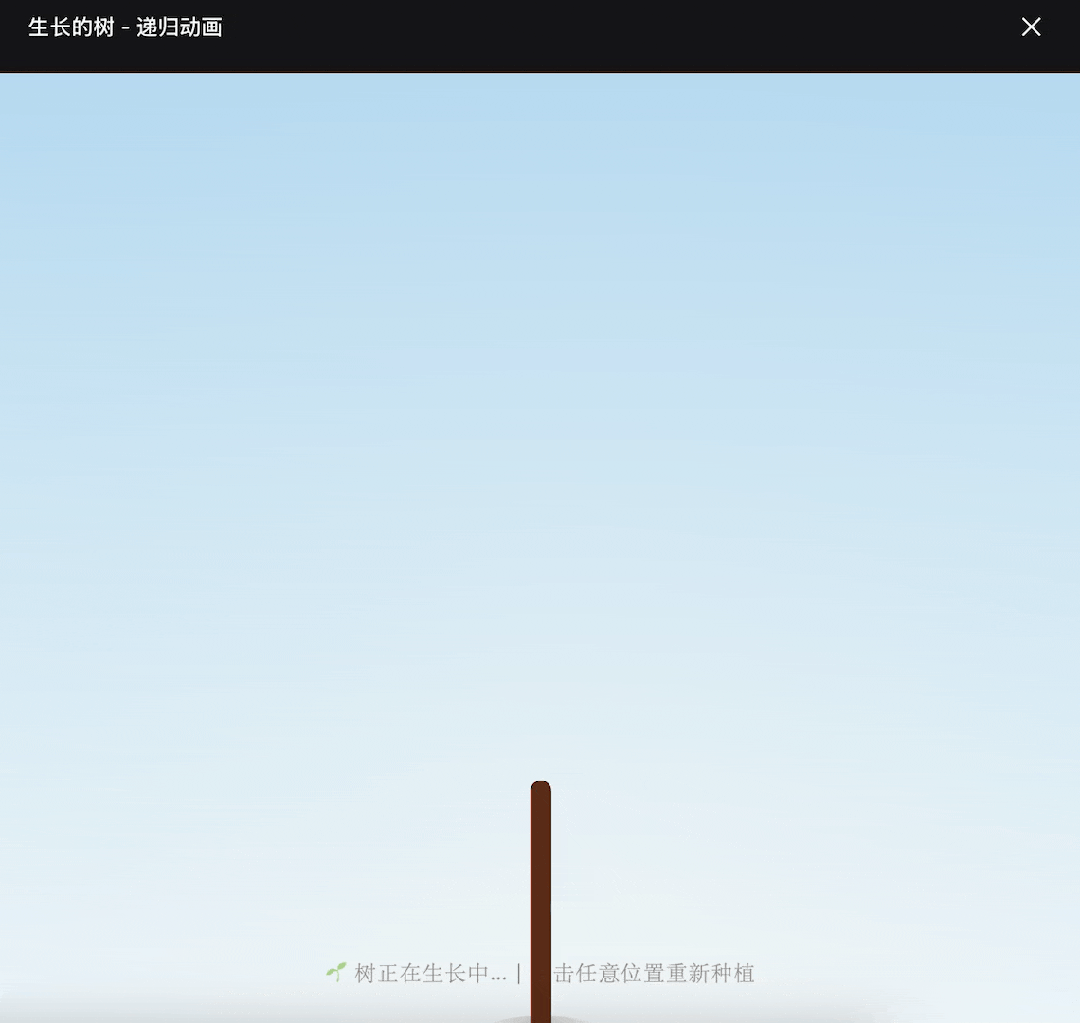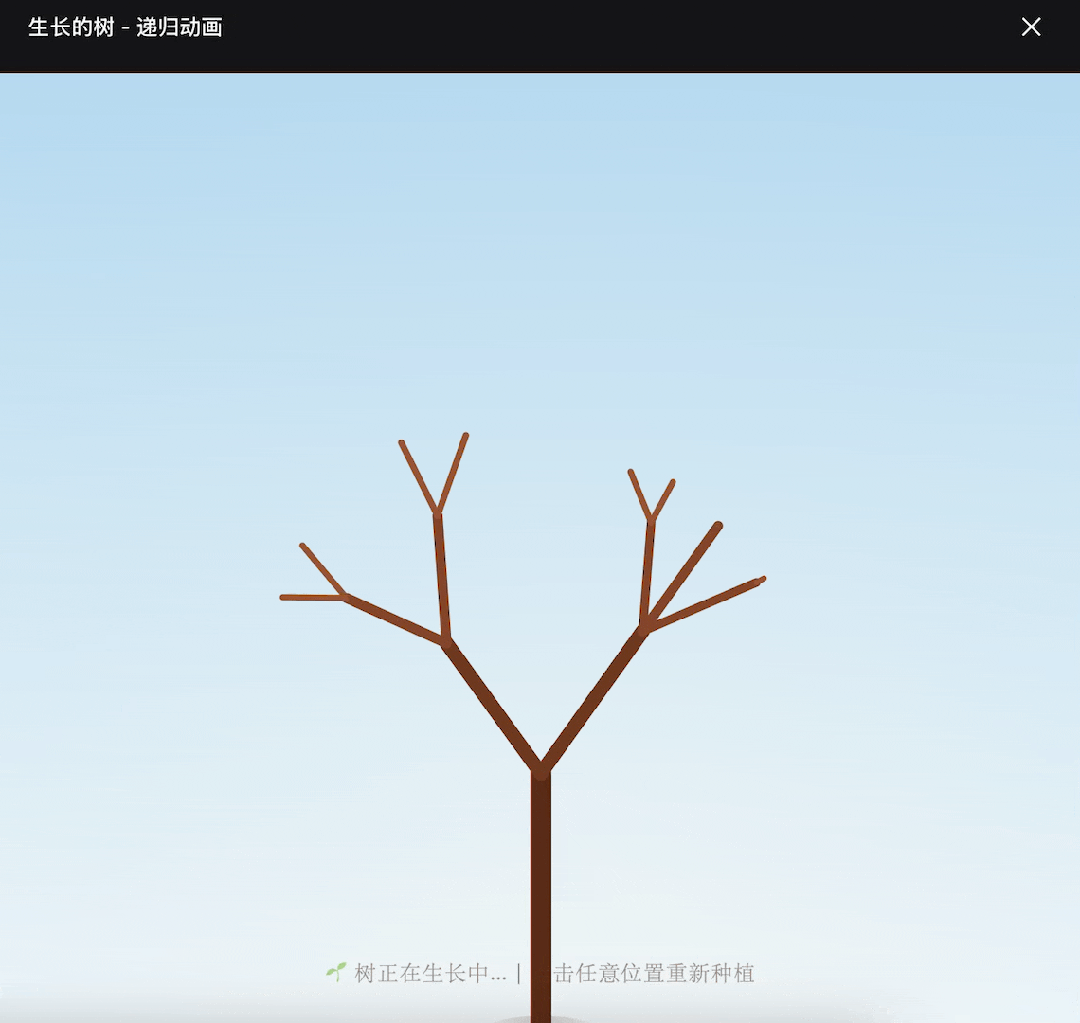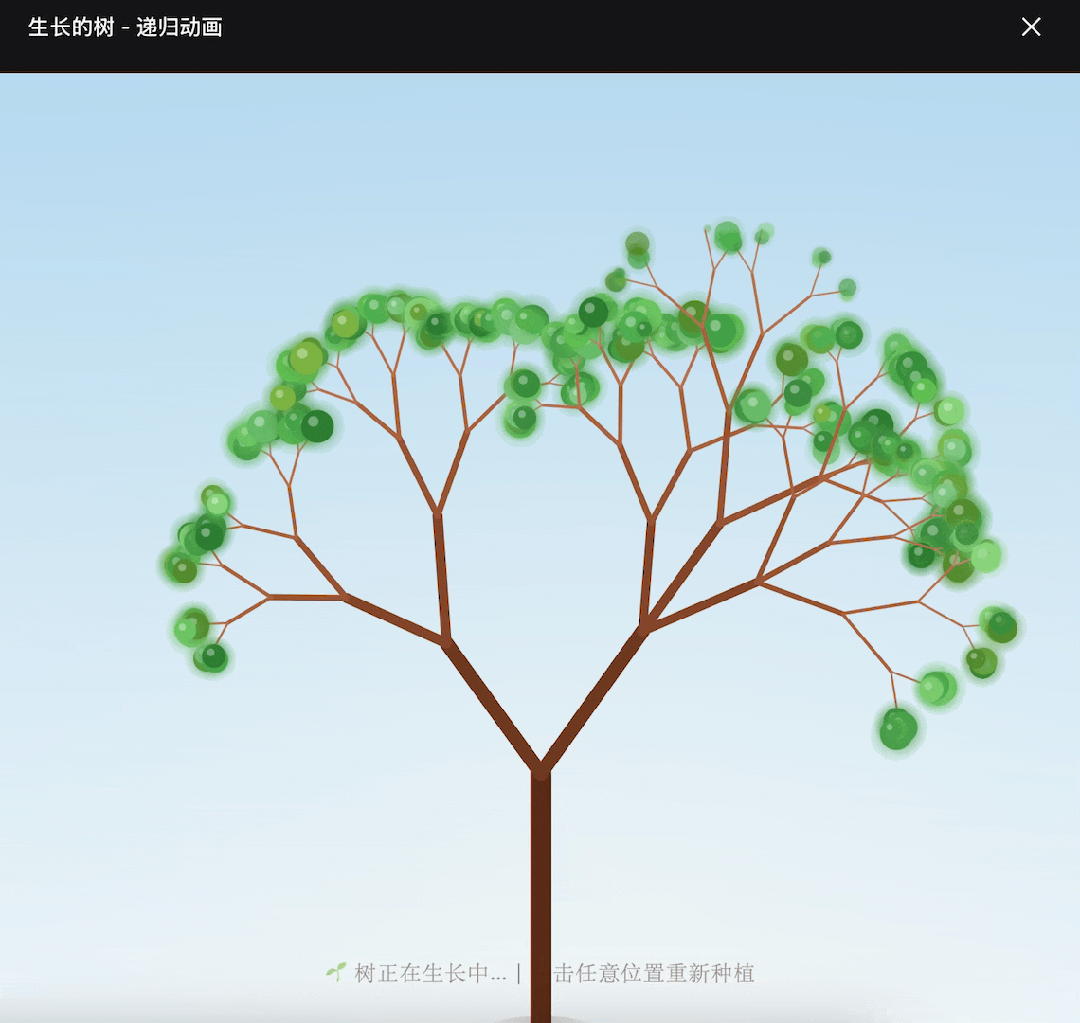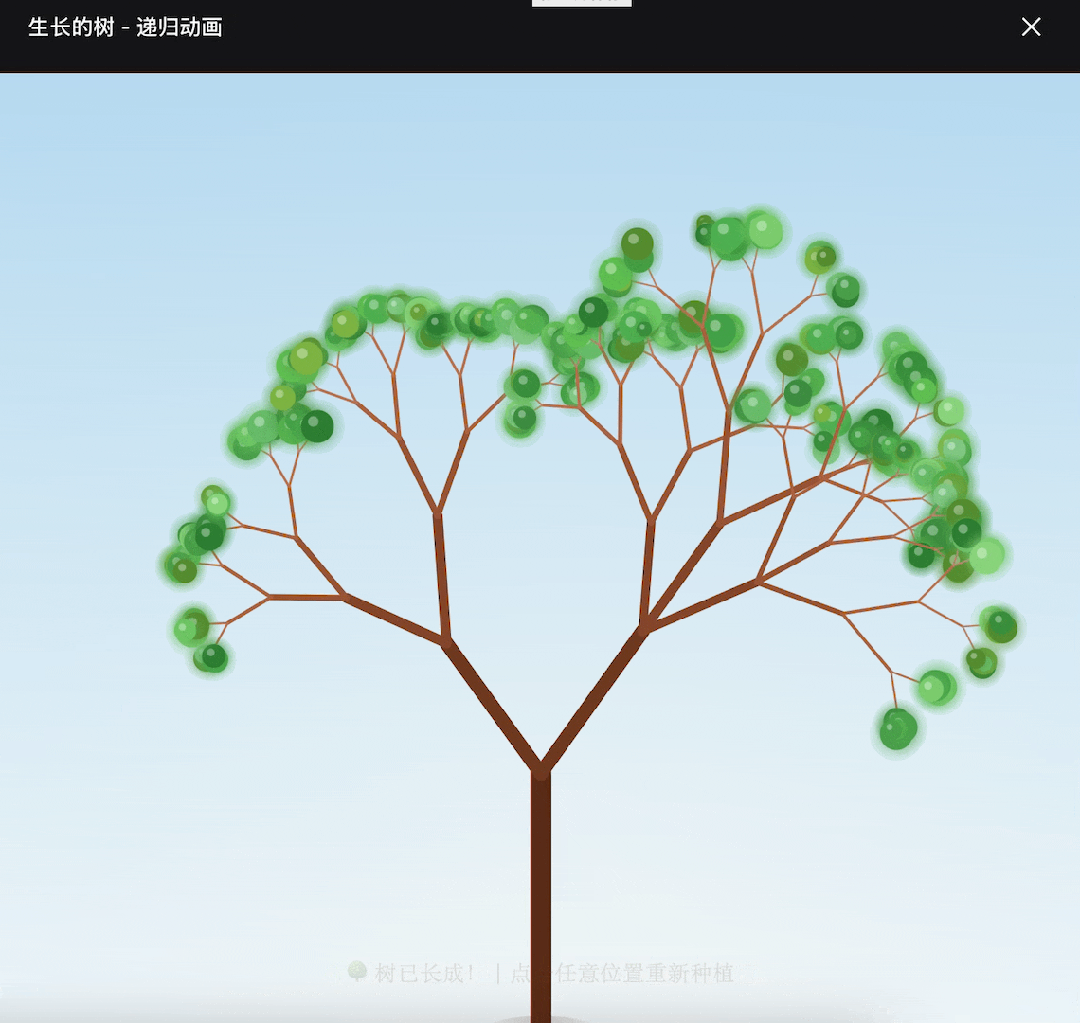
At this point, the overall performance ceiling of DeepSeek V4 is not very high and lacks stability.
However, the programming model under the Claude Code framework tends to perform better, so the next step is to integrate DeepSeek V4 with Claude Code for further testing.
It produced an initialization error in a 2048 game, making it unplayable.
This was a minor error, but it highlighted the high probability of hallucinations in DeepSeek V4, even in relatively simple tasks.
Next, we attempted a new scenario, simulating Conway’s Game of Life on a web page, with a duration of one minute and the ability to add new seeds in real-time via mouse clicks, with difficulty between Excel and tree growth simulation.
Prompt:
Implement a complete animation program for Conway’s Game of Life in a single HTML file with the following requirements:
-
Technical Constraints: Only use HTML + CSS + native JavaScript. No third-party libraries or frameworks allowed. All code must be contained within the same HTML file. No external resources (CDN, image libraries, etc.) are allowed.
-
Canvas and Rendering: Use
<canvas>as the full-screen drawing area, automatically adapting to the browser window size (100% width and height) and supporting high-resolution screens (consider devicePixelRatio). The grid should be proportionally sized (e.g., adjustable between 10px and 20px). -
Game Logic: Each cell has two states: alive/dead. Each generation updates according to classic rules: fewer than 2 neighbors → dead (isolation); 2 or 3 neighbors → alive (continuation); more than 3 neighbors → dead (overcrowding); exactly 3 neighbors → resurrected.
-
Initialization State: Randomly generate 40%-60% of alive cells initially and support a preset interesting pattern (e.g., glider + random noise mix).
-
Animation Requirements: The animation should run for 60 seconds, with a frame rate controlled between 10-30 FPS (to avoid excessive calculations). After 60 seconds, it should automatically stop updating and remain in the final state.
-
Visual Effects: Alive cells should be represented as bright green squares, dead cells as black or dark backgrounds. Optional slight visual enhancements (e.g., fading, trailing effects) are allowed but must not affect performance. The background should be simple, with no unnecessary UI.
-
Performance Requirements: Must use a two-dimensional array or optimized structure to store state. Avoid repeated DOM operations during updates (only use canvas redrawing). Optimize neighbor calculations to avoid O(n²) heavy implementations.
-
Enhancements (Bonus Points): Support pause/resume (space key), toggle cell states by clicking on the canvas, and reset to a random world by pressing R.
DeepSeek’s implementation results were impressive, and it indeed allowed for mouse seed addition, reactivating some cells that had entered a resting state.
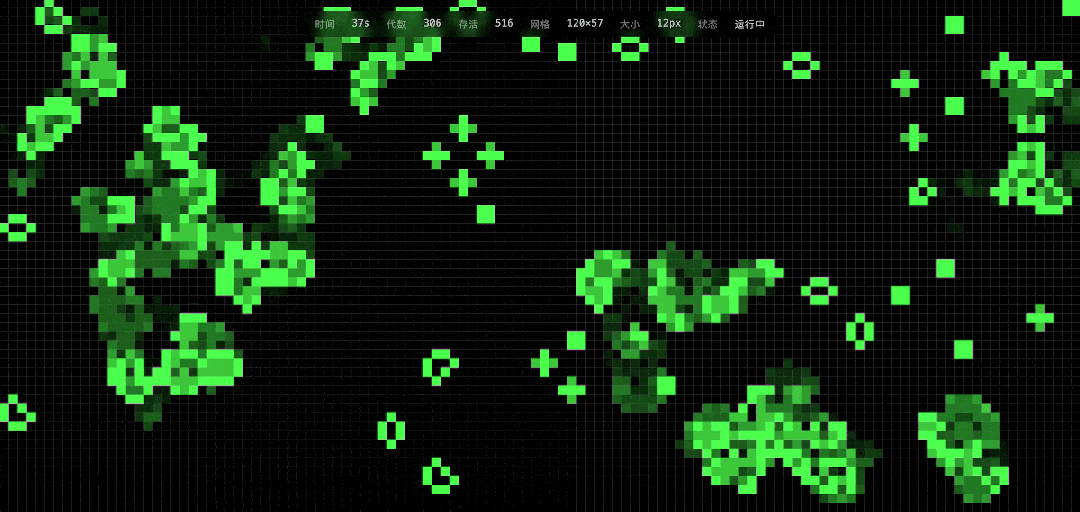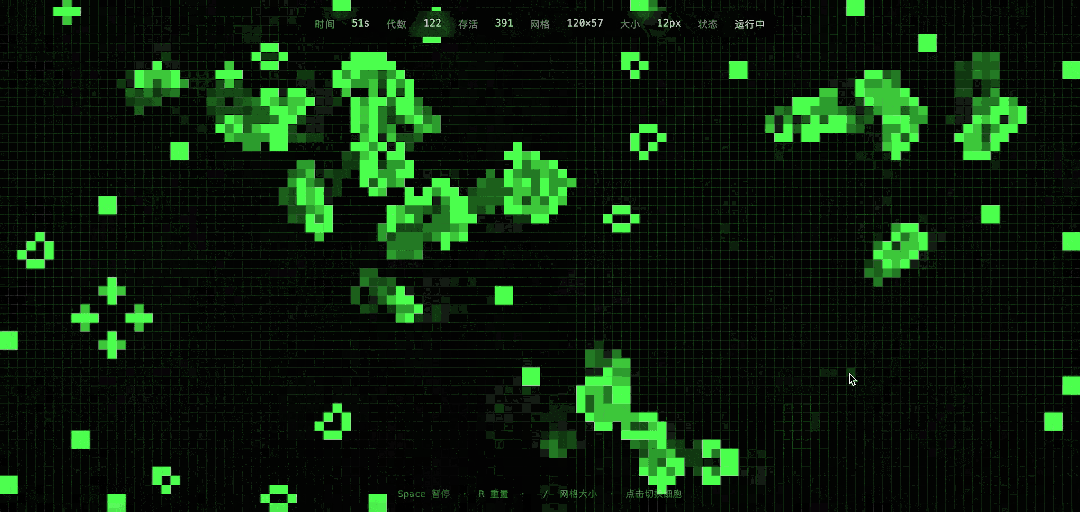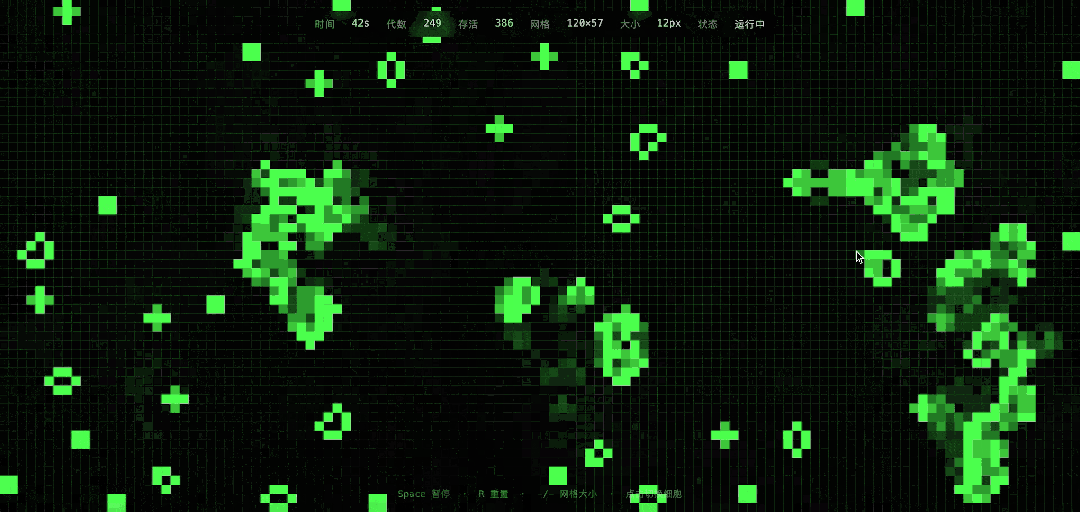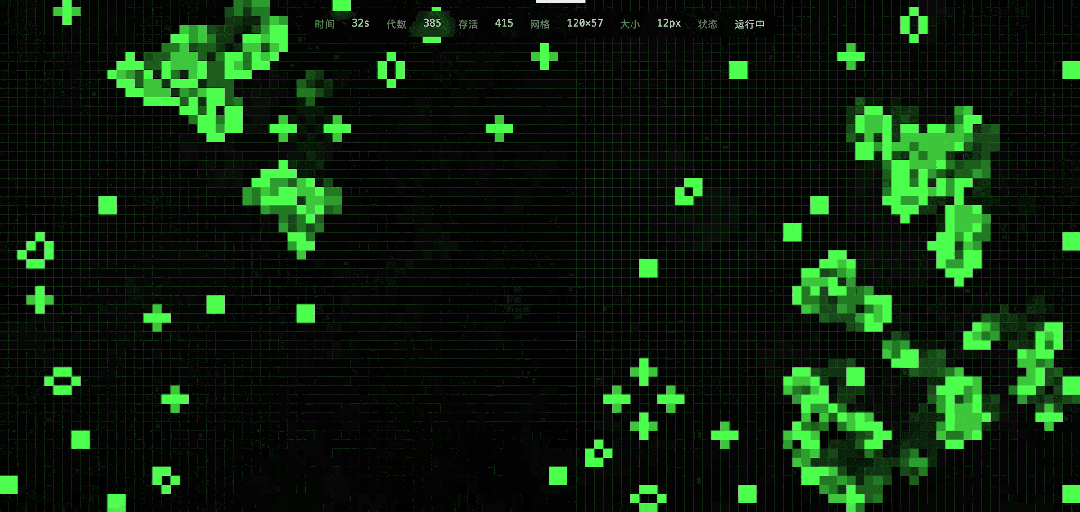
The execution time for this task was in the minute range. In comparison, GPT-5.3 generated the code almost instantaneously, akin to copy-pasting, and the program ran correctly, though the visual granularity and aesthetic quality were significantly lower.

Finally, we had DeepSeek V4 attempt the web-based Excel case again.
Under purely autonomous execution conditions, DeepSeek V4 took nearly half an hour to implement a basic version, but there were still minor errors, such as a malfunctioning alignment feature.
Given the current positioning of open-source models in the Coding Agent ecosystem, they are better suited for specific execution tasks under the control of top-tier closed-source models.
I first passed the task to GPT-5.3 for execution planning, then provided both the task and the plan to DeepSeek V4 for execution.
This time, DeepSeek V4 produced a beautiful result with almost no errors.
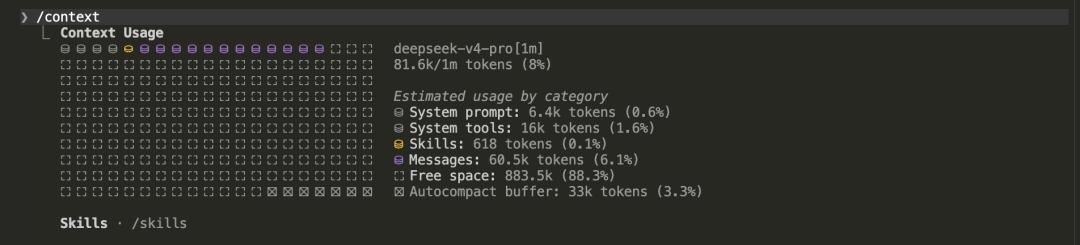
According to the context statistics from Claude Code, the current total context amount is 81.6k tokens, occupying 8% of the context limit.
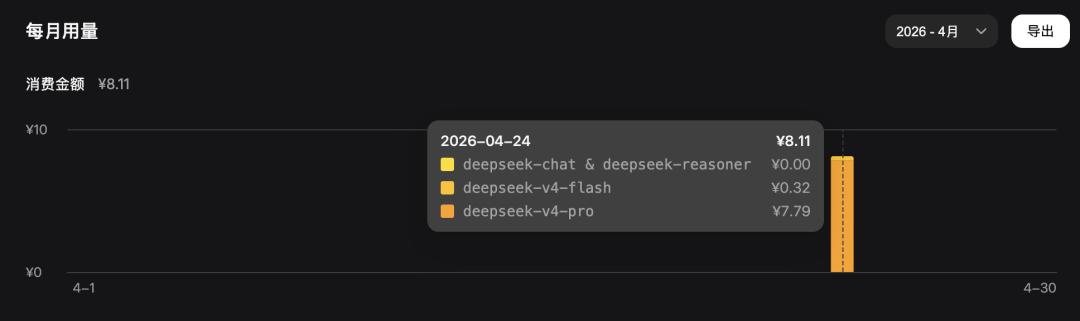
Lastly, regarding API usage, the total cost for the four tasks was around 8 RMB, almost entirely consumed by the DeepSeek V4 Pro model.
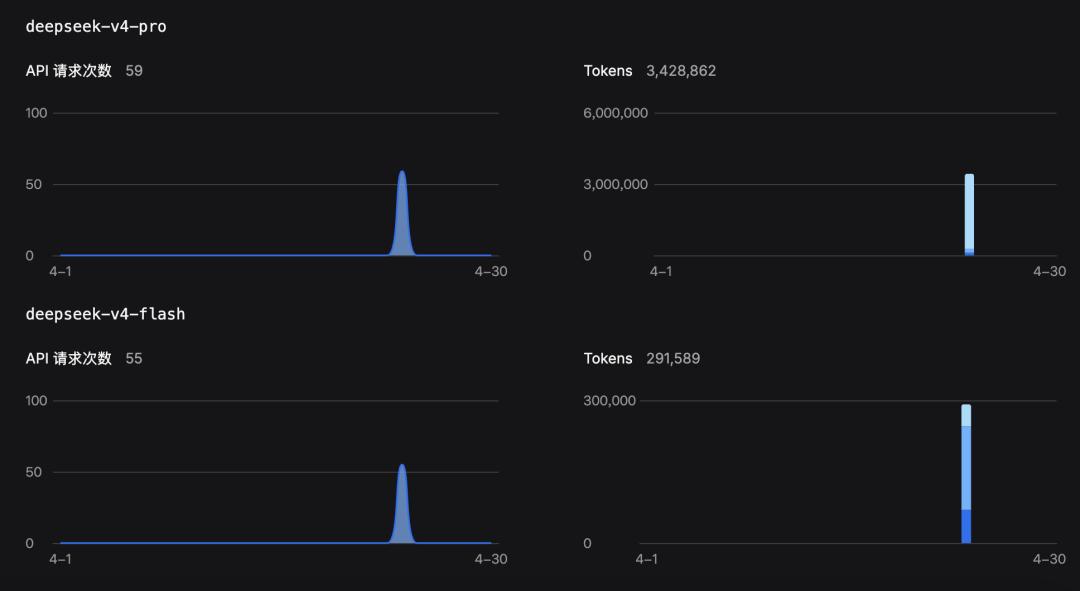
However, this does not imply that the DeepSeek V4 Flash model did not play a role; more specific data indicates that the invocation frequency of the DeepSeek V4 Flash model is comparable to that of DeepSeek V4 Pro, with token consumption one order of magnitude lower.
The evaluation concludes here.
From the current test results, the effectiveness percentage of DeepSeek V4’s million-token context is not very high, with a high hallucination rate leading to the possibility of basic errors in both simple and more challenging tasks, resulting in unstable performance. During the code review phase in Claude Code, it sometimes consumes one-third to half of the time to correct code.
Excessive thinking time may be the most awkward issue. Even the web-based Excel case is not particularly complex, yet DeepSeek V4 often takes over ten minutes to think, with total durations frequently reaching around thirty minutes.
People have largely demystified the chain of thought; it is merely an engineering approach to improve accuracy through increased computational power, which may be overlooked in the Coding Agent scenario.
The model’s upper limit makes it unlikely to take a leading role in actual programming tasks, and its execution speed is too slow. Whether disabling the Thinking mode or switching to the Flash model can ensure execution accuracy remains untested due to time constraints.
Overall, from the perspective of the cases we tested, DeepSeek V4’s performance is not as good as expected, and its capabilities seem to be somewhat unstable. However, the official technical report has candidly stated that there is still a gap compared to top-tier closed-source models, and this update merely narrows that gap, so this result is not surprising.
But still, considering its price, it’s hard to complain.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.