Introduction
Recently, numerous users have reported issues with the GLM series models, particularly in scenarios involving long contexts and high concurrency. Problems include abnormal cache hits, mixed contexts, and unclear billing. Some developers even suspect a token interference phenomenon, where one user’s context is mistakenly mixed into another user’s inference process.
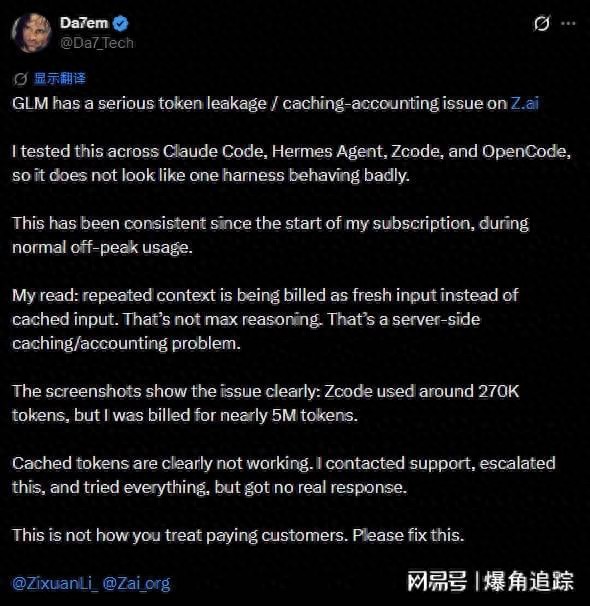
Initial Concerns
The controversy did not initially stem from billing issues. This year, some developers using GLM-5 for programming tasks found that the model occasionally outputs a large amount of meaningless characters, repetitive content, and even unrelated code snippets and thought chains. Users reported that the likelihood of these occurrences increased significantly when context lengths exceeded tens of thousands of tokens.
As discussions grew, some developers began to suspect that the problem might not be purely a model hallucination but rather an anomaly in the underlying caching mechanism of the inference system. Users noted that they saw clear code snippets, file paths, function names, and technical discussions unrelated to their current tasks in the model’s outputs, suggesting that data from different users might have mixed during inference.
Caching Mechanism and Billing
This discussion quickly attracted attention because modern large models commonly use KV Cache (key-value caching) technology to improve inference efficiency. Simply put, when users input a large amount of context, the system caches previously computed content, reducing GPU load and response time for subsequent inferences.
At the same time, many AI platforms have introduced a “cache billing” mechanism. When the system detects that a new request is highly consistent with previously cached content, it charges a significantly lower rate than normal input tokens. This means developers can substantially reduce API costs.
However, this is where the problems arise.

Some developers found that despite not resubmitting a large amount of content, they experienced abnormally high cache hit rates in their bills. Others reported significant fluctuations in the number of cached tokens for identical requests made at different times, making it difficult to explain the specific calculation logic. Consequently, questions arose about the accuracy of the cache statistics and whether users were genuinely benefiting from the advertised cache discounts.
Furthermore, some developers speculated that if the caching system malfunctions in a high-concurrency environment, it could theoretically affect not only model outputs but also cache billing results. In other words, if the system mistakenly identifies certain content as a cache hit, discrepancies could arise between what users ultimately pay and their actual consumption.
Lack of Evidence
As of now, these claims primarily come from discussions within the developer community, with no public evidence proving that Z.AI has engaged in systematic erroneous billing practices.
Notably, in April of this year, Z.AI released a technical review acknowledging that GLM-5 had experienced abnormal output issues in high-concurrency production environments. According to the official disclosure, the problem was traced back to race conditions in the KV Cache and cache synchronization errors in the inference system, rather than the quality of the model’s training. The officials stated that under extreme loads, the order of reading cached data could become abnormal, leading to garbled text, repeated outputs, and incorrect content, and that these issues have been resolved.
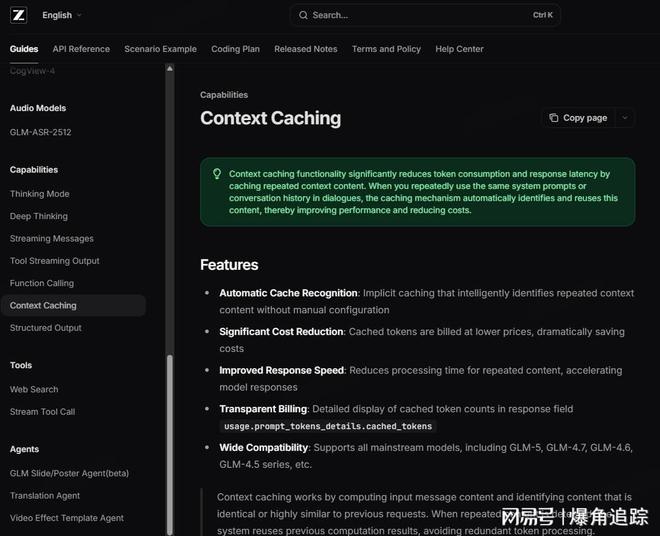
While this official statement did not admit to user data leaks, it indirectly confirmed that the caching system had indeed experienced underlying failures that affected model outputs.
Meanwhile, Z.AI’s official documentation describes the caching mechanism cautiously. It indicates that the caching feature is still in an open testing phase, and specific hit rules, cache retention times, and triggering conditions have not been fully disclosed. The officials only state that when a request hits the cache, the cost is calculated at one-fifth of the normal price.
Conclusion
Due to the lack of transparency in the underlying mechanisms, developers find it challenging to independently verify the accuracy of each cache hit, which has been a significant reason for the ongoing controversy.
The real issues of “data leakage” and “cache failure” are actually two different matters. If the model outputs garbled text or mixed contexts solely due to cache synchronization errors, the problem lies within the inference infrastructure. However, if it can be proven that a user’s private content has been fully exposed to another user, that would constitute a more serious data security incident. Currently, the latter has not received conclusive evidence support in public discussions.
As the context lengths of large models increase and cache optimization becomes more complex, the inference system has become a key factor in determining product stability. Many users focus on model parameter sizes, leaderboard rankings, and inference capabilities, but they may overlook that underlying caching, scheduling systems, and billing systems can also pose risks.
As of now, the debate over “token leakage” and “cache billing anomalies” continues to unfold, and community discussions are far from over. For Z.AI, merely fixing technical issues may not be sufficient; enhancing the transparency of the caching mechanism, providing more detailed billing explanations, and building developer trust may be the real challenges that need to be addressed.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.